When managing a lot of data, performance is usually one of the main concerns. Thankfully, BigQuery provides features such as partition to help you manage and query your data with the best possible performance.
BigQuery partition helps optimize the query performance and gives you better control over the costs associated with the use of BigQuery. Learn how it works and how to create partitioned tables with our guide.
BigQuery partition – How does it work?
Through partitioning, BigQuery automatically creates smaller chunks of a single table (partitions) based on specific criteria. For example, every day, BigQuery can generate a new table containing the data only for this particular day.
Then, when you execute a query requesting data only for this date, BigQuery reads only a specific table or a small set of them rather than an entire database. This leads to two main advantages, involving performance as well as pricing.
Performance-wise, the system can now read smaller tables more quickly, so even complex queries can become fairly efficient. As for pricing, BigQuery’s pricing model is based mostly on the size of the data a query transfers, so partitioning can effectively save you money by transferring only the required amount of data.
If you import data from your apps (e.g., Pipedrive, Airtable, and Hubspot) into BigQuery using Coupler.io, tables can also be partitioned based on the chosen criteria. More on those in the next chapter.
Different types of fields you can partition BigQuery tables by
There are mainly three types of partitioning which we further describe below:
- Time-unit column
- Ingestion time
- Integer range
In order to achieve better query performance and minimize costs, BigQuery uses a process called pruning. Pruning is when you are executing a query in a partitioned table, BigQuery will scan the partitions that match any filter used in the query and will skip the rest of the partitions.
BigQuery partition by time-unit column
This type of partitioning requires the tables to be partitioned based on a TIMESTAMP, DATE, or DATETIME column field. Using a time-unit column field BigQuery can write and read information from the partitioned tables based on these fields. For example, when you want to write a new record, BigQuery automatically searches and writes the data into the correct partition based on the time-unit column.
Based on the above column fields, BigQuery can apply different granularities so you can have more flexibility over the partitions. For example, for partitions that are using the DATE column, you can have daily, monthly, or yearly granularity based on UTC time. Let’s see this example using a yearly granularity:
| Value | Partition (yearly) |
| DATE(2016, 12, 25) | 2016 |
| DATE(2018, 11, 21) | 2018 |
| DATE(2018, 4, 8) | 2018 |
Ingestion-time partitioning
Ingestion-time partitioning is using the time when BigQuery ingests the data into partition the table in multiple chunks. In a similar way to the time-unit column partitioning you can choose between hourly, daily, monthly and yearly granularity for the partitions.
In order to be able to execute the queries, BigQuery creates two pseudo columns called _PARTITIONTIME and _PARTITIONDATE, where it stores the ingestion time for each row truncated by your granularity of choice (e.g., monthly). Below is an example of the partitions using the monthly granularity of the ingestion time:
| Ingestion time | _PARTITIONTIME | Partition (monthly) |
| 2016-12-25 18:08:04 | 2016-12-25 18:08:04 | 201612 |
| 2018-11-21 09:24:54 | 2018-11-21 09:24:54 | 201811 |
| 2018-04-08 23:19:11 | 2018-04-08 23:19:11 | 201804 |
Integer-range partitioning
Last but not least is the integer-range partitioning, where BigQuery partitions a table based on an integer-type column. In order to create an integer-range partition table, you need to provide four arguments:
- The integer-type column name.
- The starting value for range partitioning (this is inclusive, so whatever value you’re using will be included in the partitions).
- The ending value for range partitioning (this is exclusive, so whatever value you’re using will not be included in the partitions).
- The interval between the starting and ending values.
Based on the above, BigQuery will create a set of partitions, so the values in the integer-type column name (argument 1) will be split into ranges of interval (argument 4).
Any rows that contain values lower than the starting value (argument 2) or equal or more than the ending value (argument 3) will be put into a partition named __UNPARTITIONED__ and any rows that the integer-type column value is NULL will go into a partition named __NULL__.
Can I partition by multiple columns in BigQuery?
Unfortunately, BigQuery does not allow partitioning a table using multiple columns yet. While there might be some hacks to override this, you cannot ensure the appropriate performance efficiency.
How to create a new BigQuery partitioned table
In order to create a new partitioned table, you can follow a similar process as for creating a standard table along with providing some additional table options:
- Visit your BigQuery console.
- Select your data set where the table should be created.
- Click on “Create a table”.

- In the next screen, you can add your table name, columns and, in the bottom side of this window, you have the option to select a partitioning type. For this example, we’re creating a “customers” table with 4 columns, and we have all three options to partition:
- customer_id (
INTEGERtype) - first_name (
STRINGtype) - last_name (
STRINGtype) - date_registered (
DATEtype)
- customer_id (

- By selecting each different type of partitioning, we can see the various options that that go along with it:
- If we want to partition by ingestion time we must also provide the partitioning ingestion time granularity (hour, day, month, year).
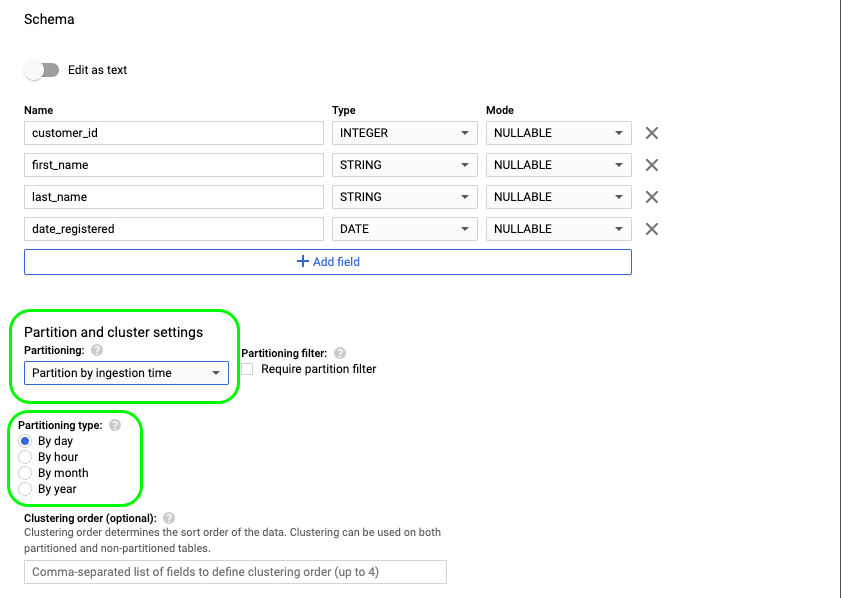
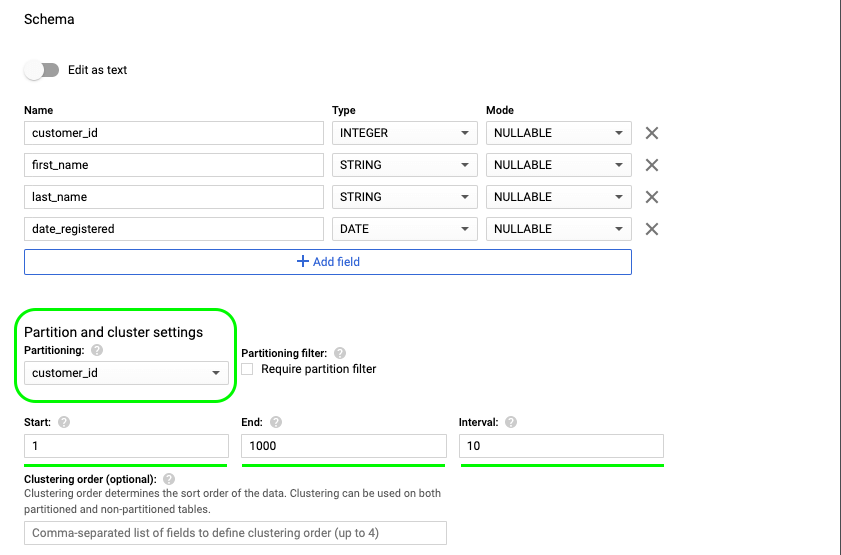
- If we choose to partition the table based on an integer-range and column (e.g., customer_id), we must also provide the start value, end value and the interval.
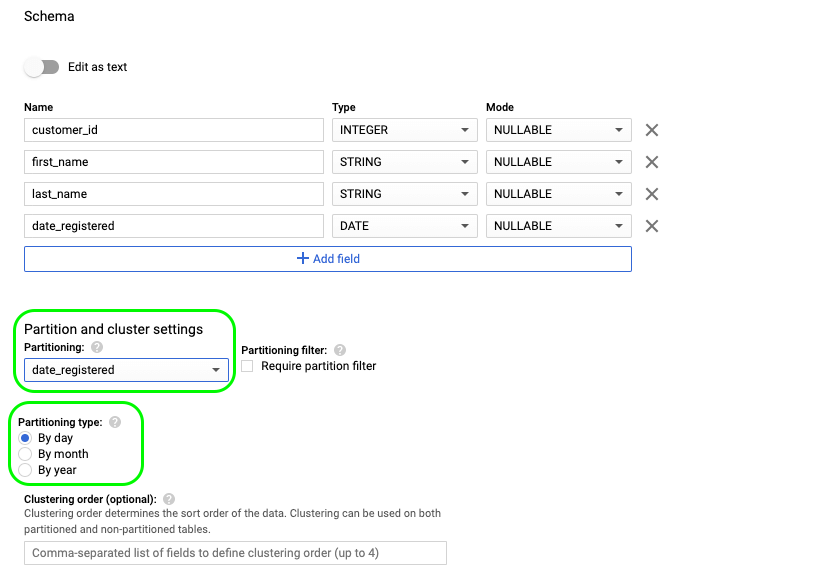
- Finally, if we want to partition the table based on the
date_registeredfield, we must also provide the respective granularity (day, month, year).
- After providing the necessary options (as shown in previous steps), we can click “Create table” at the bottom of the page and have this partitioned table created in our data set.
Now that your table is created, you can transfer your data to it using Coupler.io and its BigQuery integrations. You can then start analyzing it efficiently and without the excessive costs normally associated with querying huge data sets.
How to partition an existing BigQuery table
In order to partition an existing table, we must use a query to create a new table and provide the necessary options for the partitioning. It’s important to note that, when using a query, you can only copy an existing BigQuery table and partition it either by an integer-range column or by a time-unit column, as it’s not possible to use ingestion-time partitioning.
So let’s see an example of how we can copy a non-partitioned table like the one we had in the previous examples and partition it by the time-unit column.
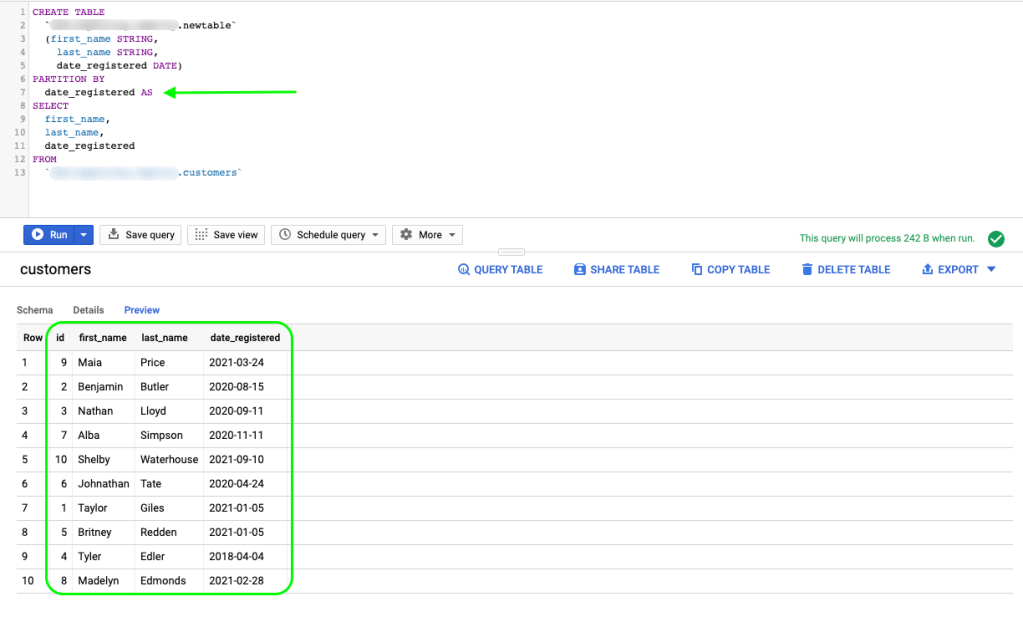
Below is the query we used:
CREATE TABLE
`project-id.dataset-id.newtable`
(first_name STRING,
last_name STRING,
date_registered DATE)
PARTITION BY
date_registered AS
SELECT
first_name,
last_name,
date_registered
FROM
`project-id.dataset-id.customers`
And as you can see a new table is created, partitioned by date_registered, and using the default options (day granularity):
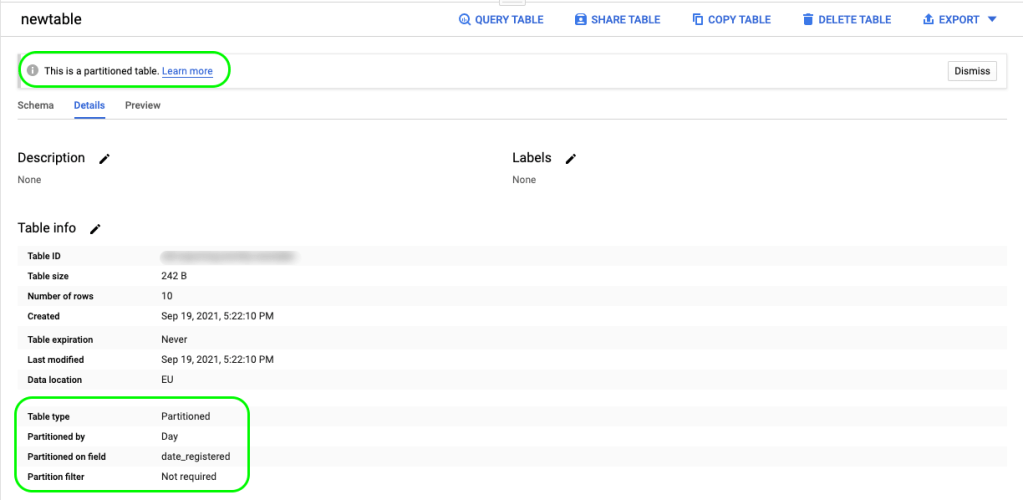
BigQuery partitioned table expiration
When you are partitioning a table using a time-unit or ingestion-time as the partition type, you can specify a partition expiration time. This configuration option specifies how long BigQuery will keep the data in a partition. This setting is applied to all partitions but for flexibility purposes is calculated for each partition separately and can be changed.
After the expiration date of a partition is passed, BigQuery deletes all data in this particular partition. In order to alter an existing table partition expiration date, you can just use the ALTER_TABLE command and adjust the expiration date option, as shown below:
ALTER TABLE `project-id.mydataset.newtable` SET OPTIONS ( partition_expiration_days=12 )
This query will expand the partition table expiration date by 12 days since the query is executed.
How to query a BigQuery partitioned table
Querying a partitioned table is not much more complicated than querying a standard table in BigQuery. There are some cases though where you can take advantage of the partitioning to find specific data and minimize the querying cost.
Querying a time-unit partitioned table
Querying a time-unit partitioned table has no difference from querying a standard table, with the exception that when you are using the time-unit column that is used for the partitioning as a filter, BigQuery knows to only search your data in the specific partitions.
Querying an ingestion-time partitioned table
A great way to take advantage of an ingestion-time partitioned table is to use a pseudocolumn, such as _PARTITIONDATE or _PARTITIONTIME.
In the below example, we query our ingestion-time partitioned table to get all the data ingested between 18 September, 2021 and 21 September, 2021.
SELECT
*
FROM
`project-id.dataset.newtable`
WHERE
_PARTITIONTIME BETWEEN TIMESTAMP('2021-09-18') AND TIMESTAMP('2021-09-21')

Querying an integer-range partitioned table
Querying an integer-range partition table is no different than querying a standard non-partitioned one. When the integer-type column used for the partitioning is included in a filter, BigQuery prunes the partitions and reduces the query cost by accessing only the necessary partitions.
How to copy a BigQuery partitioned table
Copying an existing table to a new destination table is the same whether the table is a standard table or a partitioned table, as during the copying process, all the partitioning information is carried through.
How to copy an individual partition
There are some cases where you might only want to copy an individual partition to a new table. Unfortunately, this action is not supported by the Cloud Console, and you can only use the bq command-line tool.
For example, let’s say we have the customer’s table partitioned by date_registered and we want to copy a specific day partition to another table. We can use the partition decorator ($) to denote the specific partition and copy it to the new table as shown below:
bq cp -a 'project-id.dataset.customers$20210130' project-id.dataset.newtable
BigQuery Partitioned tables limitations
BigQuery partitioned tables also come with limitations. As we’ve mentioned already, we do not have the ability to partition a table using multiple columns (or non-time/non-integer columns).
Moreover, partitioned tables are only available through Standard SQL dialect and we cannot use legacy SQL to query or write results to them.
Finally, integer-range partition tables come with two specific limitations:
- The partitioning column must be an integer column. This column can have
NULLvalues. - The partitioning column must be a top-level field as we cannot partition over nested fields (e.g., Records or Arrays)
BigQuery Partitioned tables pricing
BigQuery partitioned tables come with no additional pricing. Just like the standard tables, you can create and use partitioned tables in BigQuery and your charges will be based on the data stored in the partitions and the queries you run against them.
Using partitioned tables can help you minimize the costs because you can limit the bytes a query retrieves and optimize the associated costs.
Can I query an externally partitioned table in BigQuery
BigQuery supports querying Avro, Parquet, ORC, JSON, and CSV partitioned data that are hosted on Google Cloud Storage using a default hive partitioning layout. The directory structure of a hive partitioned table is assumed to have the same partitioning keys appearing in the same order, with a maximum of ten partition keys per table.
To load a new partitioned table based on external partitioned files you can follow the below steps:
- Visit your BigQuery console.
- Select your dataset where the table should be created.
- Click on “Create a table” and select Cloud Storage.
- Enter the path to the Cloud Storage folder, using wildcard format. For example,
my_bucket/my_files*. - Select the Source data partitioning checkbox.
- Enter the Cloud Storage URI prefix (e.g.
gs://my_bucket/my_files). - Leave Partition inference mode as Automatically infer types.

Finally, click “Create table”.
This way you can load an external partitioned table into BigQuery and then handle it as described in the previous sections.
BigQuery Partition – Should I use it?
So in this article, we went through everything you need to know about BigQuery partitioning and partitioned tables. We’ve covered how partitioning works, all the different ways you can create and query a partitioned table along its limitations and pricing.
If you’re just getting started with BigQuery and want to expand your knowledge on this amazing tool, feel free to explore our BigQuery tutorials.









