Big data is the term used to describe today’s large data sets. IBM defines big data as data sets whose size or type is beyond the ability of traditional relational databases to capture, manage, and process with low latency. Traditional databases such as MySQL and PostgreSQL cannot process big data because of its high volume, high velocity, and wide variety. Google developed a technology like BigQuery specifically to process big data. This post is an introduction to using Python to perform BigQuery CRUD operations.
Prerequisite
To follow this tutorial, you need the following installed on your machine
- Python
pip(Python package manager)virtualenv(you can usepipto install it)- Google Account
- Enable billing for your project if you have not done that yet
Connecting Python to BigQuery
To access BigQuery using Python, you need to create a new project or select an existing one from your Google Cloud Console. Also, you need a service account that has the BigQuery API enabled. To learn how to set up all of these, check out this Python to Google Sheets tutorial.
Once the service account and BigQuery API are enabled, the next step is to install all of the required dependencies. Make a project directory for this tutorial and run the commands below.
mkdir python-bigquery cd python-bigquery/
Use the venv command to create a virtual copy of the entire Python installation in a folder called env. Then set your shell to use the venv paths for Python by activating the virtual environment.
source env/bin/activate
The environment is now set up. Install the Python BigQuery Software Development Kit (SDK) as follows:
pip install --upgrade google-cloud-BigQuery
After creating a service account, a JSON file was generated and downloaded for you. This file contains credentials that Google BigQuery SDK will use to authenticate your requests to BigQuery API. Set the environment variable GOOGLE_APPLICATION_CREDENTIALS to the path of the JSON file that contains your service account key. This variable only applies to your current shell session, so if you open a new session you need to set the variable again.
export GOOGLE_APPLICATION_CREDENTIALS="/Users/godwinekuma/tutorials/python-bigquery/service-account-file.json"
Within your project directory, create a new file pybq.py, import the installed package, initialize the client to authenticate, and connect to the BigQuery API.
from google.cloud import bigquery client = bigquery.Client()
Perform a simple query to confirm that the setup has been made correctly.
from google.cloud import bigquery client = bigquery.Client()
# Perform a query.
QUERY = (
"SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` "
"WHERE state = 'TX' "
"LIMIT 100")
query_job = client.query(QUERY)
rows = query_job.result()
for row in rows:
print(row.name)
Run the script with python pybg.py. If everything is good you should see an output similar to the one below.

How to use Python for Google BigQuery datasets
Insert a dataset in BigQuery with Python
A dataset in BigQuery is synonymous with a database in conventional SQL. A dataset represents a collection of tables with their associated permissions and expiration period. Datasets are added to a specific project and require an ID and location. The code below creates a new dataset in the default Google cloud project.
from google.cloud import bigquery
client = bigquery.Client()
def create_dataset(dataset_id):
dataset_ref = bigquery.DatasetReference.from_string(dataset_id, default_project=client.project)
dataset = bigquery.Dataset(dataset_ref)
dataset.location = "US"
dataset = client.create_dataset(dataset)
print("Created dataset {}.{}".format(client.project, dataset.dataset_id))
create_dataset(dataset_id="your-project.your_dataset-id")
client.create_dataset raises google.api_core.exceptions.Conflict if the dataset with the same ID already exists within the project. If you check your BigQuery console, you should see the new dataset.
List datasets in BigQuery with Python
You can retrieve a list of all the datasets in a specific project using the list_datasets method.
def list_datasets():
datasets = list(client.list_datasets()) # Make an API request.
project = client.project
if datasets:
print("Datasets in project {}:".format(project))
for dataset in datasets:
print("\t{}".format(dataset.dataset_id))
else:
print("{} project does not contain any datasets.".format(project))
If you are interested in a specific dataset and know the project’s ID, you can retrieve it using the get_dataset method.
def get_dataset(dataset_id):
dataset = client.get_dataset(dataset_id) # Make an API request.
full_dataset_id = "{}.{}".format(dataset.project, dataset.dataset_id)
friendly_name = dataset.friendly_name
print(
"Got dataset '{}' with friendly_name '{}'.".format(
full_dataset_id, friendly_name
)
)
get_dataset(dataset_id="your-project.your_dataset-id")
Update a dataset in BigQuery with Python
The update_dataset is used to update a property in a dataset’s metadata or the permissions of a dataset. The code below updates the description of a dataset.
def update_dataset(dataset_id, new_description): dataset = client.get_dataset(dataset_id)
dataset.description = new_description
dataset = client.update_dataset(dataset, ["description"])
full_dataset_id = "{}.{}".format(dataset.project, dataset.dataset_id)
print(
"Updated dataset '{}' with description '{}'.".format(
full_dataset_id, dataset.description
)
)
update_dataset(dataset_id="your-project.your_dataset", new_description="This is an example dataset")
Delete a dataset in BigQuery with Python
The delete_dataset deletes a dataset from your project:
def delete_dataset(dataset_id):
client.delete_dataset(
dataset_id, delete_contents=True, not_found_ok=True
)
print("Deleted dataset '{}'.".format(dataset_id))
delete_dataset(dataset_id="your-project.your_dataset")
The delete_contents parameter is set as True to delete the dataset and its contents. Also, the not_found_ok is set as True to avoid raising an error if the dataset has already been deleted or is not found in the project.
Google BigQuery Python example: working with tables
Create a table in BigQuery with Python
Creating a table in a dataset requires a table ID and schema. The schema is an array containing the table field names and types. The code below adds a table named profile.
def create_table():
table_id = Table.from_string("your-project.your_dataset.profile")
schema = [
bigquery.SchemaField("first_name", "STRING", mode="REQUIRED"),
bigquery.SchemaField("last_name", "STRING", mode="REQUIRED"),
bigquery.SchemaField("dob", "STRING"),
bigquery.SchemaField("title", "STRING"),
bigquery.SchemaField("age", "INTEGER"),
]
table = bigquery.Table(table_id, schema=schema)
table = client.create_table(table)
print(
"Created table {}.{}.{}".format(table.project, table.dataset_id, table.table_id)
)
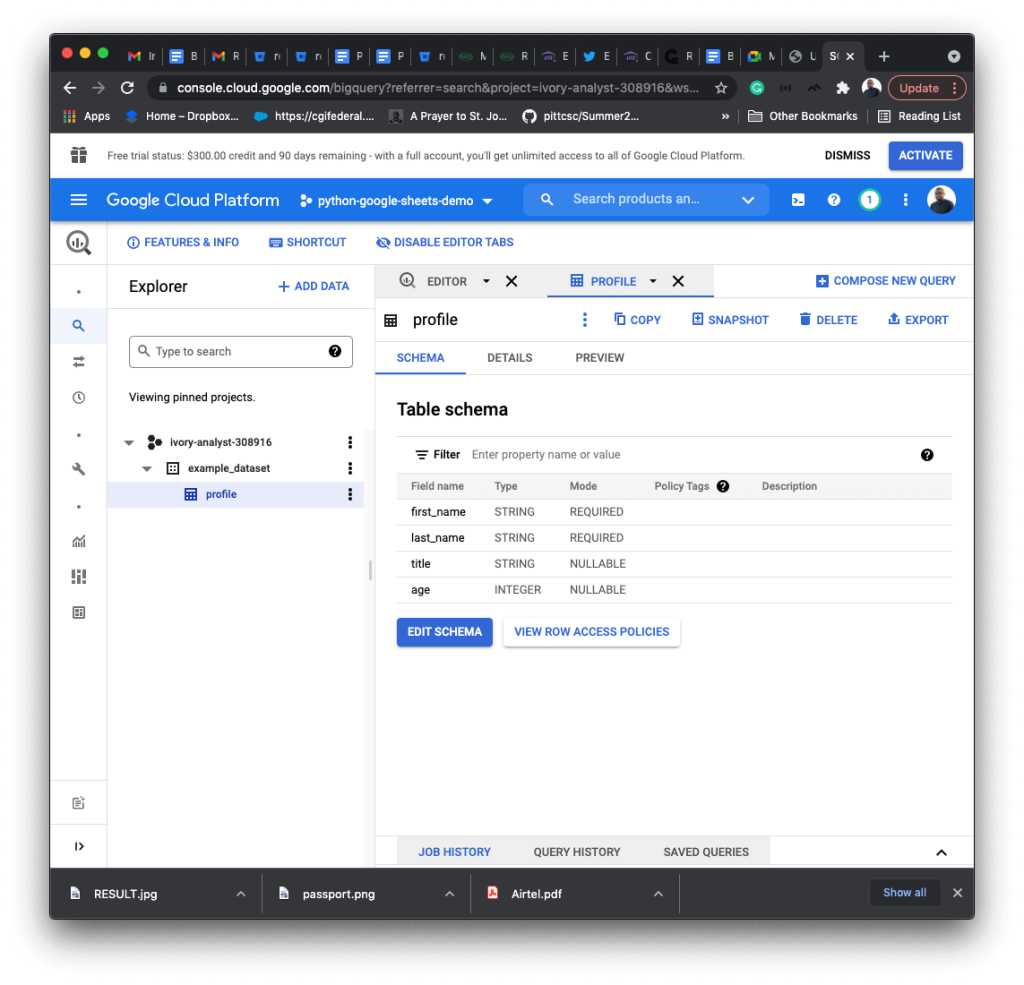
BigQuery Python insert rows
To insert data into BigQuery tables you need to have billing enabled on your account. There are a number of ways of inserting data into the tables. The simplest way is using insert_rows to add JSON data to your table.
def insert_rows():
table_id = Table.from_string("your-project.your_dataset.profile")
rows_to_insert = [
{u"first_name": u"Phred", u"last_name": "Doe", u"title": "Mr", u"age": 32},
{u"first_name": u"Phlyntstone", u"last_name": "Doe", u"title": "Mr", u"age": 25},
]
errors = client.insert_rows_json(table_id, rows_to_insert) # Make an API request.
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
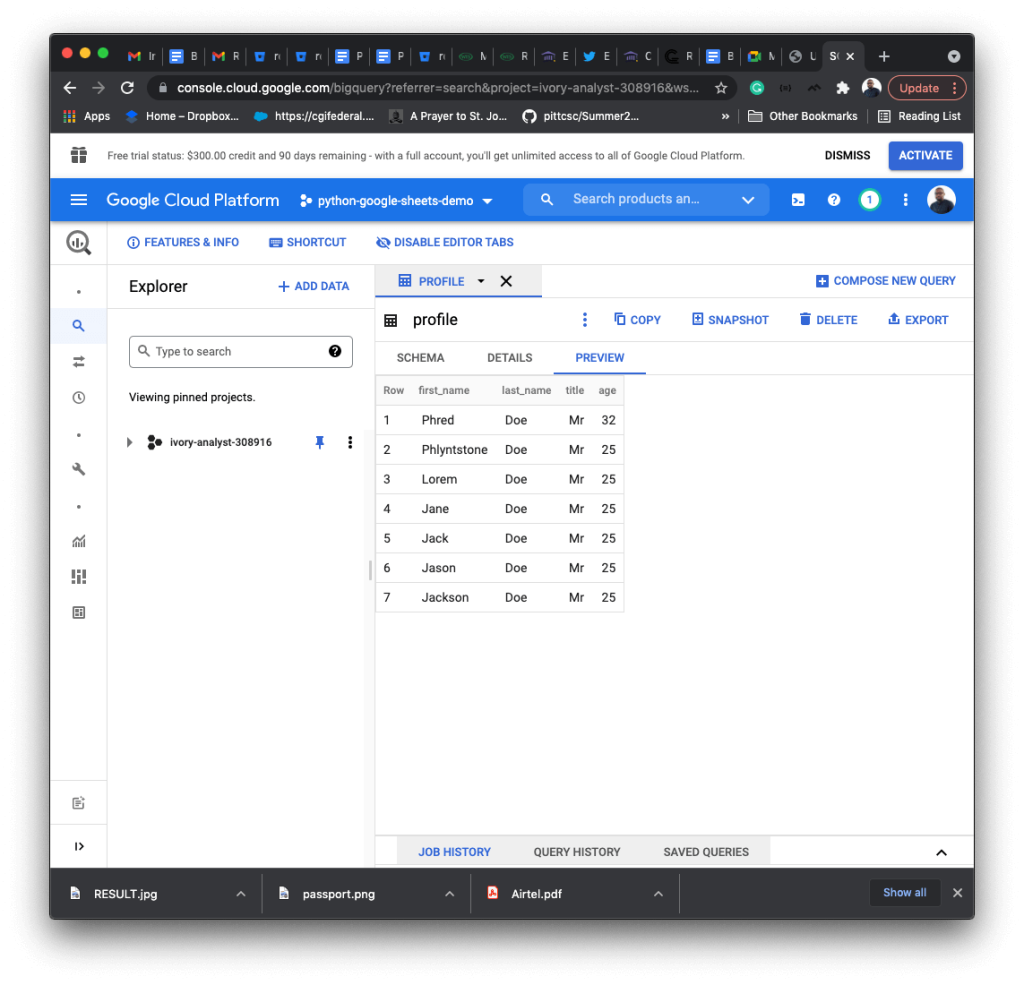
You can also insert JSON or CSV data from Google cloud storage by loading the data using load_table_from_uri.
def insert_rows_from_cloud_data():
table_id = Table.from_string("your-project.your_dataset.profile")
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("name", "STRING"),
bigquery.SchemaField("post_abbr", "STRING"),
],
source_format=bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
)
uri = "gs://cloud-samples-data/bigquery/us-states/us-states.json"
load_job = client.load_table_from_uri(
uri,
table_id,
location="US",
job_config=job_config,
)
load_job.result()
destination_table = client.get_table(table_id)
print("Loaded {} rows.".format(destination_table.num_rows))
BigQuery Python delete a table
The delete_table method is used to delete a table from a BigQuery dataset. If the table does not exist, delete_table raises google.api_core.exceptions.NotFound unless the not_found_ok is set to True.
# google.api_core.exceptions.NotFound unless not_found_ok is True.
def delete_table(table_id): client.delete_table(table_id, not_found_ok=True)
print("Deleted table '{}'.".format(table_id))
delete_table(table_id="your-project.your_dataset.profile")
BigQuery Python list tables
To list the tables in a dataset you need to add the ID of the table using the list_tables method.
def list_tables(dataset_id): tables = client.list_tables(dataset_id)
print("Tables contained in '{}':".format(dataset_id))
for table in tables:
print("{}.{}.{}".format(table.project, table.dataset_id, table.table_id))
list_tables(dataset_id="your-project.your_dataset")
BigQuery Python query result
The query method is used to query tables in a dataset. You can write regular SQL queries.
def query_datasets():
QUERY = (
"SELECT first_name FROM `your-project.your_dataset.profile` "
"WHERE age = 25 "
"LIMIT 1"
)
query_job = client.query(QUERY)
rows = query_job.result()
for row in rows:
print(row.first_name)
Export BigQuery data
You can export BigQuery data as CSV to a Google cloud bucket using the extract_table method.
def export_dataset(bucket_name, project, dataset_id, table_id): destination_uri = "gs://{}/{}".format(bucket_name, "profiles.csv")
dataset_ref = bigquery.DatasetReference(project, dataset_id)
table_ref = dataset_ref.table(table_id)
extract_job = client.extract_table(
table_ref,
destination_uri,
location="US",
)
extract_job.result()
print(
"Exported {}:{}.{} to {}".format(project, dataset_id, table_id, destination_uri)
)
export_dataset(
bucket_name="your-google-cloud-bucket-name",
project="your-project-id",
dataset_id="your-dataset-id",
table_id="profiles"
)
The no-code alternative to using Python for exporting BigQuery data to Google Sheets or Excel
If you don’t want to waste time writing Python code to export BigQuery to a Google cloud bucket, you can instead use a no-code alternative such as Coupler.io. It lets you import BigQuery data into Google Sheets and Excel. The best part is that you can schedule periodic exports of your data. This is also a good solution for business analysts with little to no coding skills who need BigQuery data for business analysis and decision making.
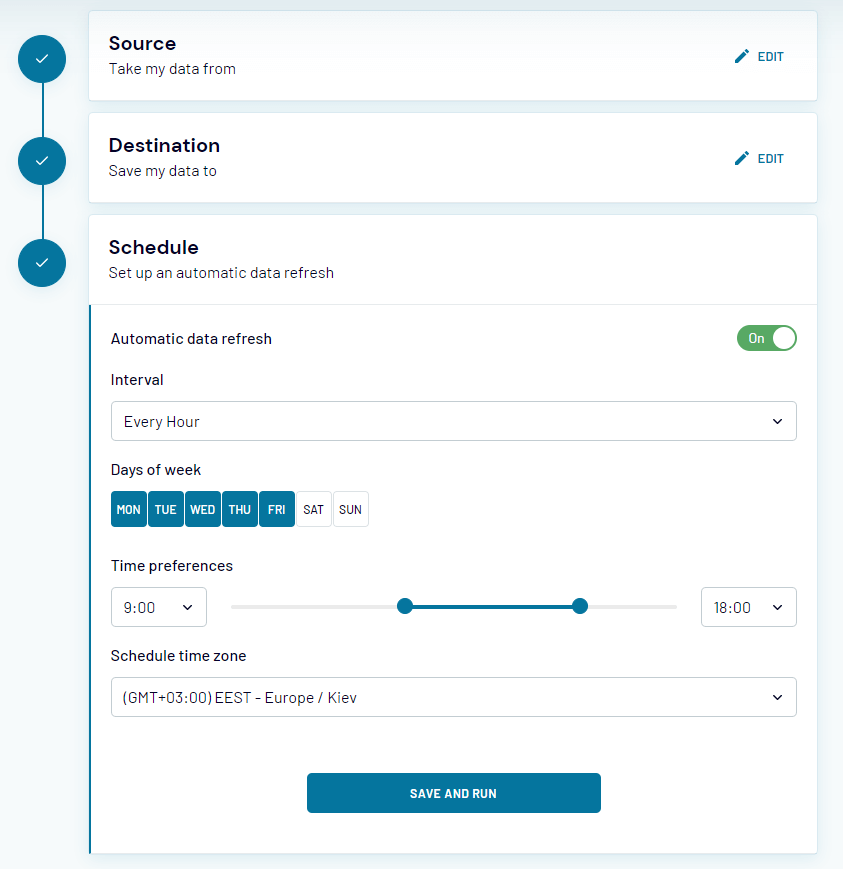
Check out more about the BigQuery integrations available with Coupler.io.
BigQuery Python or BigQuery UI
BigQuery offers a lot more functionality than we have shown here. Should you be using BigQuery UI or Python or any other programming language to work with BigQuery? It really depends on what you are doing. If you are an analyst making decisions with existing data, UI would be your best bet or even using a no-code integration. If you are a developer that stores data to BigQuery and your code is in Python then you would need to use Python.
Choose the best method that meets your needs to make your data manipulation flow as conveniently as possible. Good luck!
