In the previous episodes, I’ve explained the fundamentals:
Now let’s talk about how to scale your prompts.
Because once you move beyond one-off requests into workflows (multi-step campaigns, client deliverables, automated systems), you need to understand the technical rails your prompts run on.
This article is about turning prompt mastery into repeatable workflows, team assets, and production-ready processes. I’m pulling back the curtain on how LLMs actually process your words, and how that knowledge turns you from a prompt writer into a prompt architect.
Prompt engineering for LLMs
You don’t have to be a machine learning engineer to think like one, but understanding how LLMs work under the hood will make you 10x more effective at scale.
Contrary to popular belief, language models don’t read letters. What?
Yes, they read tokens.
A token is a chunk of text. Sometimes it’s a word. Sometimes it’s half a word. Sometimes it’s just punctuation.
- The word Marketing = 2 token
- The word Unbelievable = 3 tokens
- Hello! = 2 tokens (Hello, !)
So why is this important? Well, every model has a token limit, and going over it will break your prompt or truncate your output.
| Model | Max tokens (context window) |
| GPT-5 | ~400,000 tokens |
| GPT-5 Pro (with extended reasoning) | ~400,000 tokens |
| Claude Opus 4.1 | ~200,000 tokens |
| Claude Sonnet 4.5 | ~1,000,000 tokens |
| Gemini 2.5 Pro | ~2,000,000 tokens |
Note: These limits include both input and output. If you paste a long document, your available response space shrinks accordingly.
Tip: Use tools like OpenAI Tokenizer to check your prompt length.
Context windows: Memory boundaries
A context window is how much memory the model can “see” at once.
Once you pass that window:
- Earlier messages disappear from memory
- Responses might get inconsistent
- Quality drops (especially for recursive/agentic use cases)
To manage context:
- Chunk large inputs
- Use summaries or condensed context
- Store in external memory (e.g., with Coupler.io or LangChain) and connect to structured data sources
This is crucial for enterprise-scale workflows or multi-step systems.
Why this matters: Instead of dumping entire CSVs into your context window, Coupler.io lets AI query data sets from your sources to get the relevant subset needed for each task. This keeps your prompts clean, your context usage efficient, and your token costs under control while giving AI access to your complete data infrastructure.
Model constraints: What LLMs can’t do (yet)
Despite their brilliance, models have limits:
- No native real-time knowledge: Models are trained on data up to a specific cutoff date. Without tool integrations (like web search or live data connections), they don’t know what happened after training. However, modern implementations often include real-time tools—so the model can access current information, just not natively.
Modern models like GPT-5 include built-in web search capabilities, and Claude can connect to live data through MCP (Model Context Protocol) servers. So while models don’t have native real-time knowledge from training, they increasingly have tool access that bridges this gap.
- No persistent long-term memory: Most models don’t remember previous conversations unless you’re in the same session or using memory features explicitly designed for retention.
- No automatic data awareness: Models can’t access your CRM, analytics, or databases unless explicitly connected through integrations like Coupler.io, which lets AI query live data sources rather than relying on stale uploads.
- Stochastic output by default: The same prompt may return different results across runs due to the probabilistic nature of generation. While technical users can sometimes adjust temperature settings for deterministic behavior, most production tools don’t expose this control. Instead, focus on what you can have direct impact on: providing consistent examples, clear constraints, and explicit output formats to reduce variability.
Key takeaway: Understanding these constraints helps you build workarounds (tool integrations, memory systems, deterministic settings) rather than fighting against the model’s nature.
Working with the model, not against it
We’re gonna say it again: AI is your friend!
To maximize output quality:
- Be explicit: Don’t assume the model “knows what you mean”
- Use formatting instructions: Tables, bullet points, sections
- Avoid overstuffing: A focused prompt beats a long-winded one
- Chain prompts: Split complex instructions into smaller steps
Instead of:
Write a report, analyze this table, generate slides, and summarize a video.
Try:
- Connect your data set or upload a table → summarize
- Generate a report from the summary
- Ask:
What slides should I create from this?
This modular strategy works better with both OpenAI and Anthropic models, and it future-proofs your system for scale.
Structured prompting techniques
When you’re working with AI tools inside real business workflows, structure isn’t optional. It’s the only way to go from “this prompt worked once” to “this workflow performs daily.”
Structured prompting doesn’t just make things easier. It makes things transferable, testable, and traceable. You can hand a template to a new team member and trust the output. You can automate insights without babysitting every input. You can build processes that don’t fall apart the moment someone leaves.
Let’s walk through what that looks like across high-leverage business scenarios.
1. Templates and prompt frameworks that scale
The key is making it easily accessible! Use MCP servers or prompt platforms for easy access. If team members can’t quickly find and use the prompts, even the best prompt book will be ignored. Accessibility and ease of use are more important than having the most comprehensive collection.
This technique is ideal when multiple people are asking the same question but keep reinventing the prompt and getting inconsistent results.
Templates stop the guesswork. They lock in clarity from the start: What’s the role? What’s the task? What’s the format? What context do we always forget to include?
You can peek at some real-world examples:
Finance:
Weekly variance report across departments
➤ Prompt: You are a senior financial analyst. Based on this dataset, provide (1) week-over-week change by department, (2) highlight any departments >10% variance, (3) flag potential anomalies with short explanations.
Marketing:
Report preparation for stakeholders.
➤ Prompt: I need your help analyzing marketing performance for July 2025 and preparing reports for my stakeholders. What data do you have access to via my Coupler.io MCP server connection?
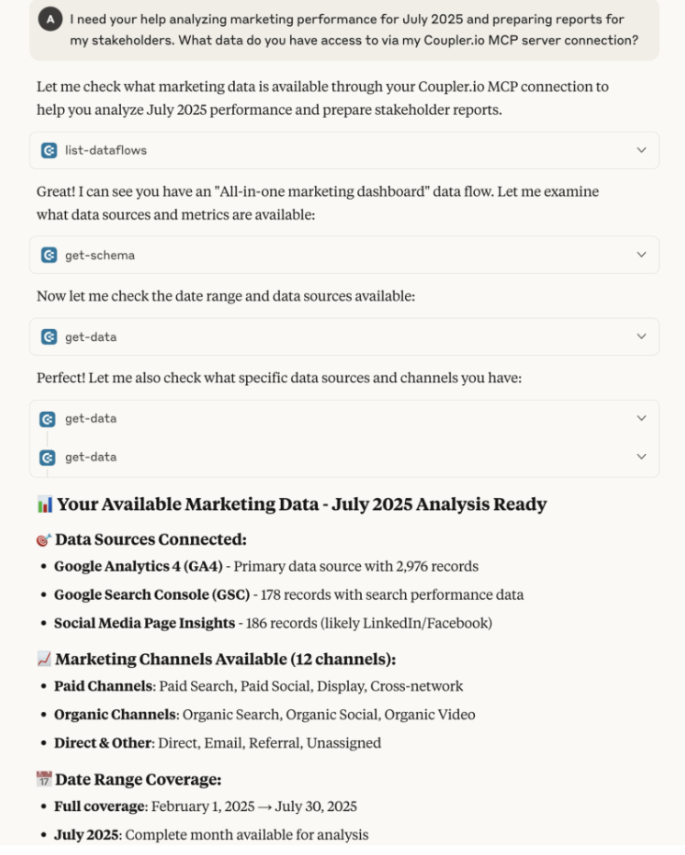
Notice how this prompt doesn’t include any uploaded data? The AI accesses metrics directly through the MCP server connection using Coupler.io. This approach eliminates manual data exports, reduces token usage, and ensures the analysis always reflects current performance.
Ops:
Late shipments overview for regional logistics team
➤ Prompt: You're an operations coordinator reviewing supply chain performance. Surface all shipments delayed >48 hours across NA, EMEA, and APAC. Summarize in table format with region, shipment ID, delay time, and issue reason if available.
These are just clear prompts that focus on precision, so the AI knows what game it’s playing.
2. JSON and XML formatting for complex outputs
This is ideal when the output is intended for sending elsewhere instead of just reading. But here’s what most people miss: structuring your prompt with JSON or XML also improves performance.
Well-organized prompts help the model parse instructions faster and more accurately. Clean structure in equals clean structure out.
Why structure your prompts? When you format complex instructions using JSON or XML, you give the model clear boundaries. Even simple markdown formatting works!
It knows exactly what each part of your request means. This reduces confusion and improves consistency, especially for multi-step tasks or workflows with lots of variables. Let’s take an example of a structured prompt:
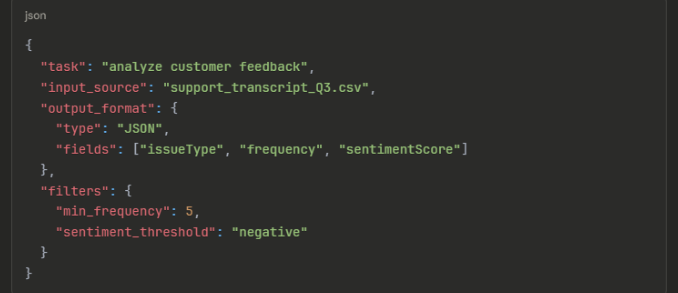
This beats writing a paragraph that says analyze the customer feedback from the Q3 support transcript and return the issues in JSON with issue type, frequency, and sentiment score, but only if they appear at least 5 times and are negative. Although we understand that this takes time to get used to using daily.
This brings us to the next question: When structure your outputs?
For the cases when you don’t want paragraphs. You want clean, structured data you can plug into a dashboard, API, or spreadsheet. JSON and XML are the go-to formats everywhere now.
Let’s look at some real-world examples:
Revenue dashboards
➤ Prompt: Summarize monthly sales by product category in JSON with keys: categoryName, unitsSold, totalRevenue, conversionRate.
→ Used by: RevOps leader feeding data into a Coupler.io-powered Looker dashboard. No cleanup needed.
The output JSON will need to be processed further to create dashboard links, but the structured format makes integration straightforward.
Customer feedback loop
➤ Prompt: Return top 5 customer complaints from this support transcript in XML. Each entry should include issueType, frequency, and sentimentScore.
→ Used by: CX manager piping clean issues into Zendesk to generate proactive resolution workflows.
Marketing campaign analysis
➤ Prompt: You are a marketing analyst. Extract campaign performance metrics into JSON format: campaignName, platform, spend, impressions, clicks, conversions, CPA. Include only campaigns with spend >$1000. Format for import into our reporting dashboard.
→ Used by: Marketing team syncing campaign data across platforms without manual data entry.
It is all about designing structured bridges between your tools.
3. Prompt engineering tools & systems (Langfuse, MCP servers, internal libraries)
What are these tools? Let’s cut through the jargon.
When your company’s running 50-200 prompts across teams, and you’re losing track of what works, you need prompt management systems. If your best prompt lives in someone’s Notion file or Slack DM, it’s already lost. You need centralized, searchable, versioned prompt libraries that turn one team’s breakthrough into company-wide leverage.
📊 According to The 2025 State of AI Engineering Survey, 69% of high-performing AI teams now track and manage prompts through an internal tool.
Here are the most widely used tools among real engineering and marketing teams who use LLMs seriously:
Prompt engineering tools
Prompt management platforms are essential for anyone doing serious work with AI. These tools help you store, organize, and reuse effective prompts rather than starting from scratch each time or losing track of what worked well.
Here are the most widely used tools among real engineering and marketing teams who use LLMs seriously:
Langfuse (The GitHub of prompts)
Langfuse is an observability and prompt management platform that can be used for tracking, versioning, and optimizing prompts. Think of it as a content management system (CMS), but for prompts instead of blog posts.
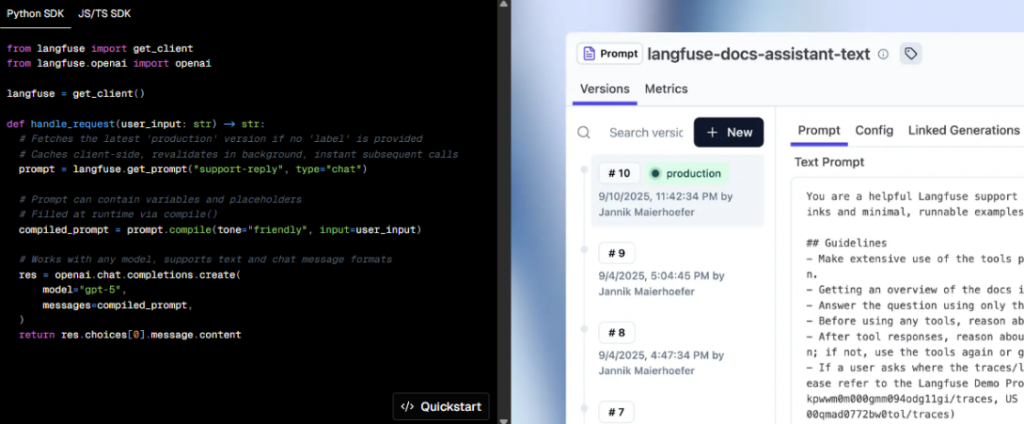
What it lets you do:
- Track every prompt + response with rich metadata (model, latency, token usage)
- Group runs by version to see how prompt changes impact results
- Flag bad outputs and annotate where things went wrong
- Tag sessions by user, prompt, or project
- Run A/B tests between prompt variations
- Store and version prompts like code commits
Whether you’re testing a new summarization prompt or debugging hallucinations, Langfuse gives you a full paper trail.
Teams love it for auditing and prompt A/B testing, especially in regulated or customer-facing applications.
Note: By the way, Langfuse also has an MCP server specifically for prompt management integration with Claude and other AI tools.
Use case: The growth team runs 3 onboarding prompt variants via Langfuse and tracks which one drives the highest signup-to-retain conversion. Underperformers get archived; top performers get version-controlled.
PromptLayer
PromptLayer acts like Google Analytics for your GPT calls.
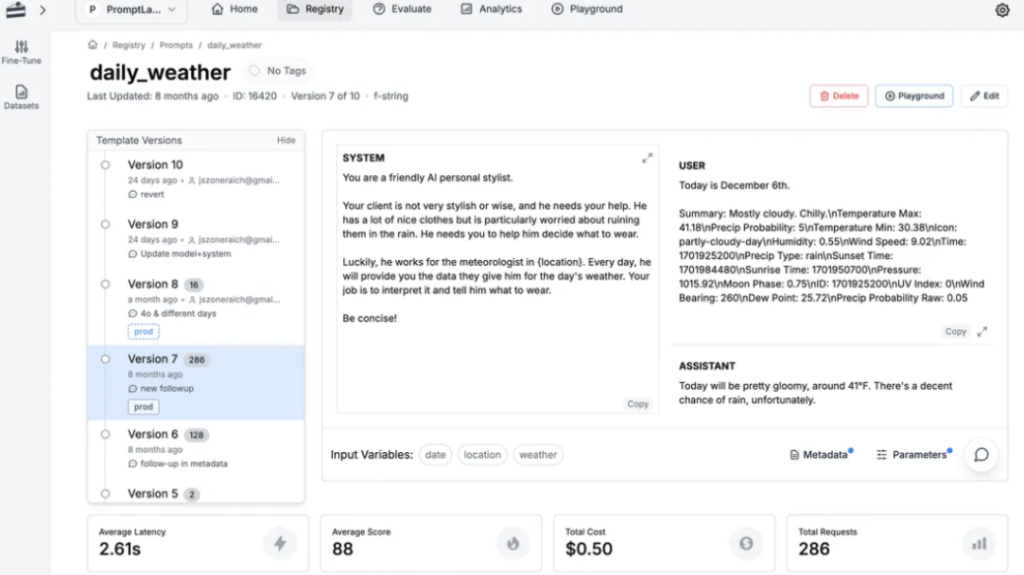
It lets you:
- Log every OpenAI call (input + output)
- Track metrics like latency, cost, token usage
- Create prompt versions and monitor their performance over time
- Label runs by feature or experiment
It is particularly useful for devs and product teams alike, especially when shipping LLM-powered features to production.
Use case: A product team tracks the performance of their customer support chatbot prompts across different user segments, identifying which prompts lead to the highest resolution rates.
MCP servers
MCP servers (Model Context Protocol servers) organize and serve prompts to your AI workflows. Picture a library catalog system. Instead of hunting through folders for the right prompt, your tools can automatically pull the correct, up-to-date version based on what task you’re running.
Internal prompt libraries or prompt books
Internal prompt libraries are custom storage systems where teams keep, tag, and version their prompts. Some companies use Notion. Others build something in Airtable or Google Sheets. Larger teams might use dedicated tools like PromptLayer or custom solutions. These can be as simple as shared folders or as complex as full databases.
Other tools worth knowing
Here are a few more players:
- PromptOps: Focuses on prompt deployment pipelines and compliance
- Promptitude.io: Geared toward marketers and builders who want a GUI to tweak and compare prompts
- Promptable / ChainForge: More experimental, but great for testing multi-step chains and prompt trees visually
Your tech stack is more than just prompts. It’s prompts + data + logic + distribution.
That’s why top teams often use:
- Langfuse for logging + analytics
- Coupler.io to feed source data into prompts (CRM, Sheets, analytics)
- Zapier / Make for triggering prompts on events
- LangChain to chain complex LLM workflows
Prompts are assets. Managing them like throwaway code snippets leaves an impact on the table. Prompt libraries protect the intelligence baked into every test, iteration, and win.
Role-based prompting techniques
Roles give clarity to each member of the team. Your model is also a member of the said team, so let’s give it a role. For instance, you can brief it like you’re briefing your best-performing team lead. That’s what expert persona development unlocks.
Expert persona development
By defining a clear role, you give the model a brain to think with.
Let’s take an example:
You are a seasoned Chief Marketing Officer with 15+ years of experience optimizing digital campaigns across Facebook, Google, LinkedIn, and emerging channels…
This sets the stage. Now pair that with:
- Context:
You’re preparing an executive summary for a startup’s Series B investor deck. - Instruction:
Create a 200-word summary outlining CAC trends and ROAS forecasts. - Format:
Return as a numbered list with bulletproof stats and actionable insights.
Roles create memory → Context fuels relevance → Structure sharpens results.
You can build persona libraries for:
- Marketing experts
- Legal reviewers
- Financial controllers
- Healthcare specialists
- Government policy advisors
And simulate decisions that are in line with each domain’s logic.
Prompt engineering best practices
You’ve got great prompts. But can you version them? Improve them over time? Spot when they actually got worse? Probably not, but you can follow how professionals do it.
Here’s how professional teams do it, especially when using platforms like Langfuse to manage large-scale prompt ops.
Documentation & version control
The biggest mistake prompt engineers make is not tracking changes. Sounds pretty avoidable, right? It is.
Just like software, prompts evolve. That means you need a way to document:
- What changed
- Why it changed
- What result it produced
Langfuse makes this painless. It automatically logs:
- Input/output examples
- Model parameters (temperature, top_p, etc.)
- Response quality (if feedback is added)
- Prompt version diffs
This is essential for debugging as well as:
- Reproducing great results
- Diagnosing failures
- Collaborating across teams
Bonus: Good prompt docs make onboarding easier for new teammates or beginners and help non-technical members understand how your system works.
Ethics and bias mitigation
LLMs reflect the data they’re trained on, and that means they can echo stereotypes, toxic language, or just weird assumptions.
You don’t always control the model weights, but you do control the prompt.
Always remember to include constraints like:
Avoid making assumptions based on race, gender, or age.Be neutral and factual; do not speculate or insert opinion.
Test across diverse inputs: names, locations, roles, demographics.
If your output changes based on user identity, flag it.
Some teams even use “red teaming” prompts and test edge cases that might trigger biased output.
A/B testing for prompts
Never assume your prompt is the best prompt.
Test it.
A/B testing for LLM prompts means sending the same input to multiple prompt versions and seeing which performs best.
Measure:
- Accuracy or completeness (manual or programmatic scoring)
- User ratings (thumbs up/down, emoji, feedback text)
- Business outcomes (e.g., conversion rate, click-through, task success)
Langfuse, PromptLayer, and even custom tools can run A/B tests at scale and help you quantify which phrasing works best.
For example:
| Variant | Instruction | Avg score |
| A | Summarize this text in 3 bullet points. | 3.2/5 |
| B | Summarize in 3 crisp, bolded bullets, each under 15 words. | 4.7/5 ✅ |
Even small phrasing tweaks can massively improve outcomes, especially when scaled across thousands of runs.
I focus on iterative testing rather than formal A/B testing. A/B testing works better for code generation prompts when you have the capability to compare the end result at once. The iterative approach is more practical for most use cases than setting up complex testing frameworks.
Common prompt pitfalls and how to outsmart them
Even seasoned pros run into walls when working with LLMs. But the difference between amateurs and experts is that experts know what’s actually going wrong and how to fix it without wasting hours debugging.
Here are the biggest traps we’ve seen (and how to sidestep them):
Over-engineering vs. Under-specification
Too much prompting = noise.
Too little = confusion.
A 700-word prompt with nested roles, split tasks, and embedded JSON might feel powerful, but it often leads to inconsistent results.
On the flip side, Write a better ad is way too vague. The model will guess, and it won’t guess well.
Fix: Use modular prompting.
Break tasks into smaller pieces and give clear context, goals, and output format for each step.
Try this prompt skeleton:
You are a [role]. Your task is to [goal].
Here is the context: [paste only relevant info]
Please output the following: [bullet list of outputs]
Format it as: [JSON/table/bullets/etc.]
The context overload trap
Just because a model can handle 128,000 tokens doesn’t mean it should.
Too much context:
- Increases cost
- Slows down processing
- Decreases quality, especially if the model can’t distinguish signal from noise
Fix:
- Chunk long inputs into focused segments
- Use summaries, semantic compression, or vector search
- Keep prompts tight and relevant
Data structure matters: One major cause of context overload is dumping raw, unstructured data into prompts. A 10,000-row CSV with messy headers can eat your entire context window. Instead, use structured data flows (like those from Coupler.io) that let AI query specific subsets—’ Show me top 10 accounts by revenue’—rather than processing everything at once.
Bias traps and assumption errors
LLMs can amplify subtle biases in your prompt.
Example: Write a job ad for a sales manager. Make sure he is aggressive and confident.
It sounds normal. But it encodes gender bias and assumptions about “ideal” traits.
Fix:
- Use neutral, inclusive language
- Run your prompts through bias checkers or ask:
How might this prompt lead to biased results? - A/B test for tone and framing differences across audiences
Technical limitations (and workarounds)
Models aren’t perfect, so if you’re pretending that they are, get ready to watch your pipeline get sabotaged.
Some limitations to watch for:
- Context-switching issues (sudden topic jumps)
- Stochastic behavior (random output even with same input)
- Lack of memory (unless fine-tuned or using tools like LangChain/Coupler.io)
Fixes:
- Use temperature = 0 for deterministic tasks
- Retry failed completions with adjusted prompt or few-shot examples
- Store external memory (e.g., in vector DBs or Google Sheets via Coupler)
Most models are bad at context-switching. Start a new chat if the LLM starts going wild.
Sometimes, the simplest fix is also the best.
Troubleshooting guide: When prompts go wrong
Start here when the model outputs junk:
- Bad format? → Add output instructions with examples
- Off-topic? → Tighten your context or break into steps
- Repeating or looping? → Check for prompt leakage or long context chains
- Inconsistent tone or logic? → Use role-based prompting and set temperature = 0
- Working with messy or inconsistent data? → Switch from uploaded files to structured data connections. Coupler.io provides clean, normalized data that eliminates 80% of format-related prompt failures.

Integrate your data with AI for efficient prompting
Get started for freeIf all else fails:
Start a clean session.
Residual memory can bleed across turns, especially in recursive workflows.
Version your prompts and compare performance over time using tools like Langfuse.
In short, LLMs aren’t some divine all-knowing beings.
They are simply logic machines with quirks that can be confused for magic.
And once you learn to outsmart those quirks, the results stop being “AI-generated”… and start being indistinguishable from expert human work.
Even users who understand advanced prompting techniques often assume the AI has more background knowledge about their specific situation, industry, or project than it actually does. Context is everything for AI models.
Wrapping up: From prompt dabbler to prompt pro
We must understand that prompt engineering is a new interface between humans and machines.
Whether you’re building systems, optimizing workflows, or just trying to get better answers faster, the difference lies in how well you speak the model’s language.
Start small. Document what works.
Test, tweak, and scale.
And when in doubt?
Break it into steps, give it structure, and let the model do the heavy lifting.
The three essential principles are: Role play — define who the AI should be for your specific task. Few-shot learning — provide examples of what good outputs look like. Context — always give relevant background information.
