Strings, integers, floats, constants, booleans, and special characters are all common components of datasets. When working with strings, it’s often typical to want to alter the capitalization, check for extra spaces, extract a certain portion or otherwise adjust or tweak the data in some way. Cutting the clusters and displaying just the necessary information is possible using the Google BigQuery SUBSTRING function. This function allows users to see, edit, and alter specific sections of strings and byte data.
If you’re looking to learn more about substring and string operations in Google BigQuery, then this article is a good place to start.
What is BigQuery substring?
The SUBSTRING function allows you to search for a particular character in the text data or string you’re querying. It’s also known as SUBSTR, and this will be used equally in this article.
With the help of these functions RIGHT(), LEFT(), REGEXP_SUBSTR() and SPLIT(), you can retrieve any number of substrings from a single string.
SUBSTRING SQL BigQuery syntax
SUBSTRING (value/text, starting_position, string_length)value/text– refers to the set of characters to be extracted from a given stringstarting_position– refers to the initial value of the stringstring_length– refers to the amount of characters that you want to extract
BigQuery substring example
To further understand how SUBSTRING() works, consider the following example.
In the query below, the names Janet, Lawrence, Annabella are combined using the BigQuery UNION operator. We then define 3 to represent the starting position. The SUBSTRING() function retrieves the text from that point all the way to the end.
WITH names AS (SELECT 'Janet' as name UNION ALL SELECT 'Lawrence' as name UNION ALL SELECT 'Annabella' as name) SELECT SUBSTR(name, 3) as example FROM names;
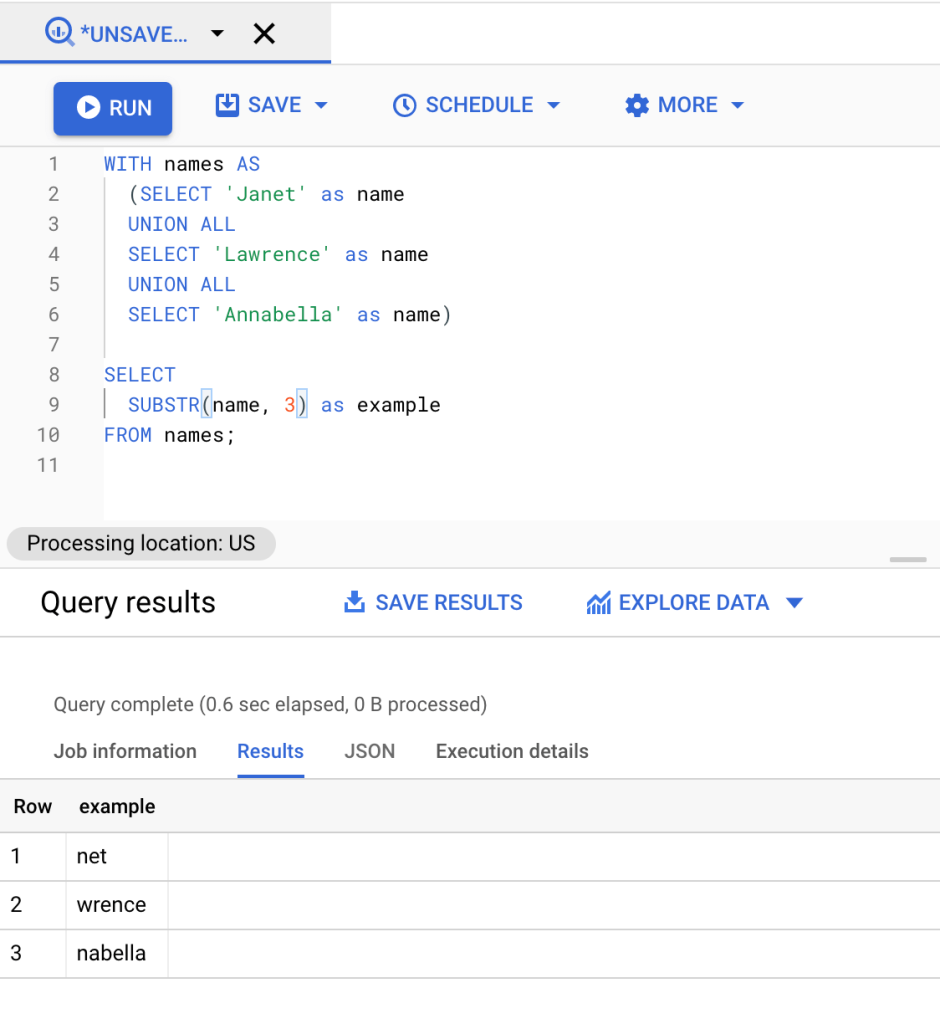
As you can see in this example, when counting the characters, you’ll start counting from 1. Since we defined 3 as our starting point, when we reach the third character the substring retrieves the text from that point.
BigQuery substring right
In this BigQuery, the rightmost characters from the specified content or arguments are returned using the RIGHT function. The syntax for this is:
RIGHT(value, length)Let’s look at the example below:
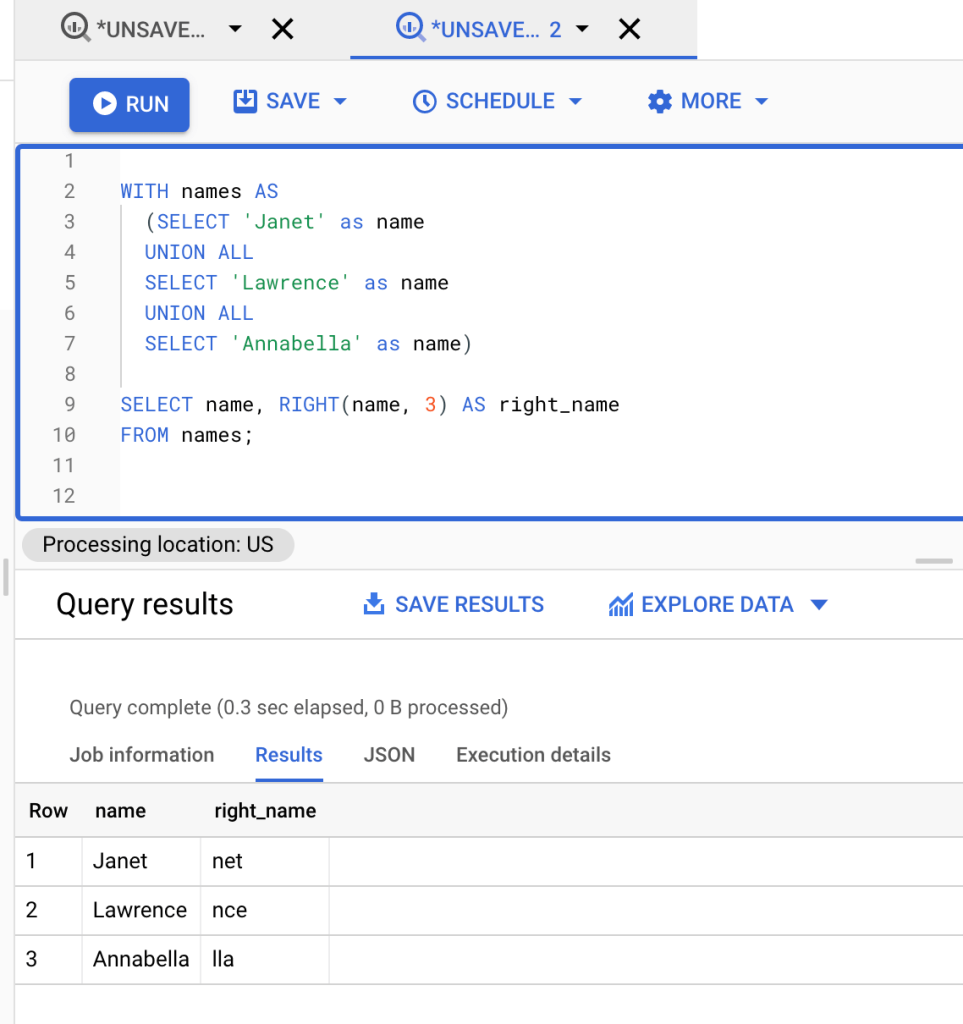
WITH names AS (SELECT 'Janet' as name UNION ALL SELECT 'Lawrence' as name UNION ALL SELECT 'Annabella' as name) SELECT name, RIGHT(name, 3) AS right_name FROM names;
The names Janet, Lawrence, Annabella are combined using the union operator. We then defined 3 as our desired value. The RIGHT() function returns the characters from the end of the text which is the right-side of the text. Thus, we now have ‘net‘, ‘nce‘, and ‘lla‘. In other words, the RIGHT() function counts three, which is the desired value and extracts three characters from the end of the text.
BigQuery substring left
In BigQuery the LEFT() function produces a result that contains the leftmost characters from the content or arguments that have been passed to it. The syntax for this is:
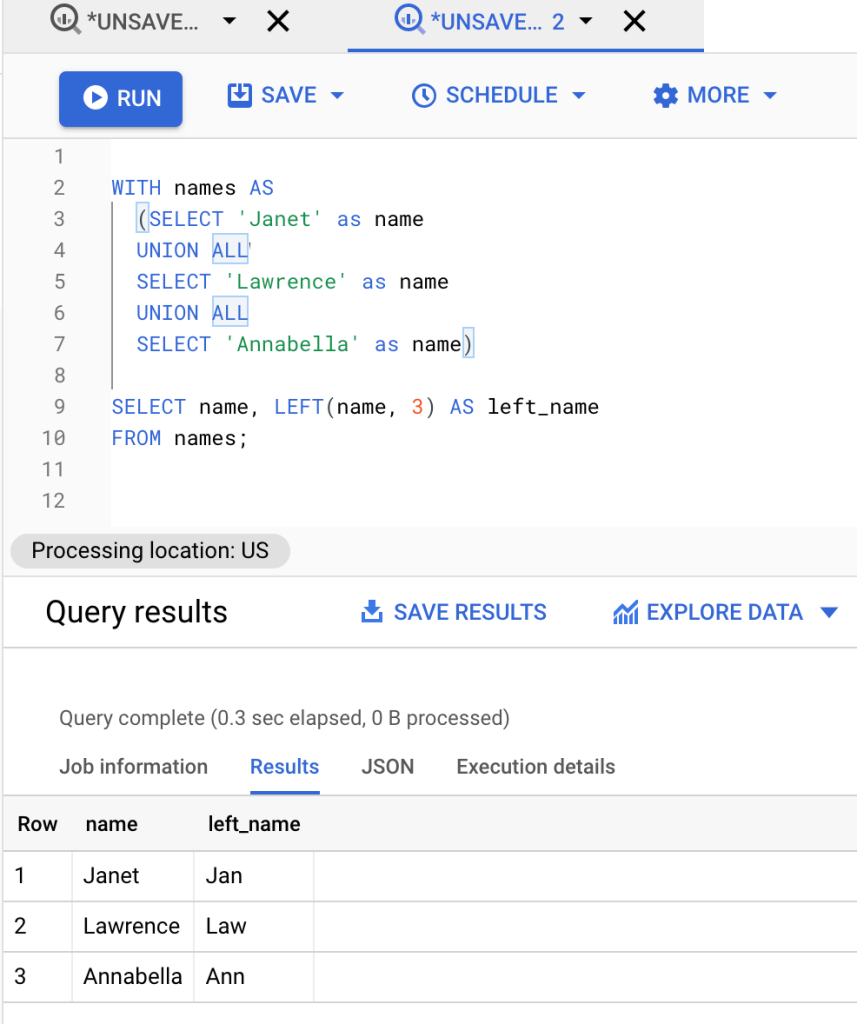
LEFT(value, length)In the following formula, the names Janet, Lawrence, Annabella are combined using the union operator. We then defined 3 as our desired value. The LEFT() function returns the characters from the beginning of the text which is the left-side of the text. Thus, we now have ‘Jan‘, ‘Law‘, and ‘Ann‘. In other words, the LEFT() function counts three, which is the desired value and extracts three characters from the beginning of the text.
WITH names AS (SELECT 'Janet' as name UNION ALL SELECT 'Lawrence' as name UNION ALL SELECT 'Annabella' as name) SELECT name, LEFT(name, 3) AS left_name FROM names;
BigQuery substring between two characters
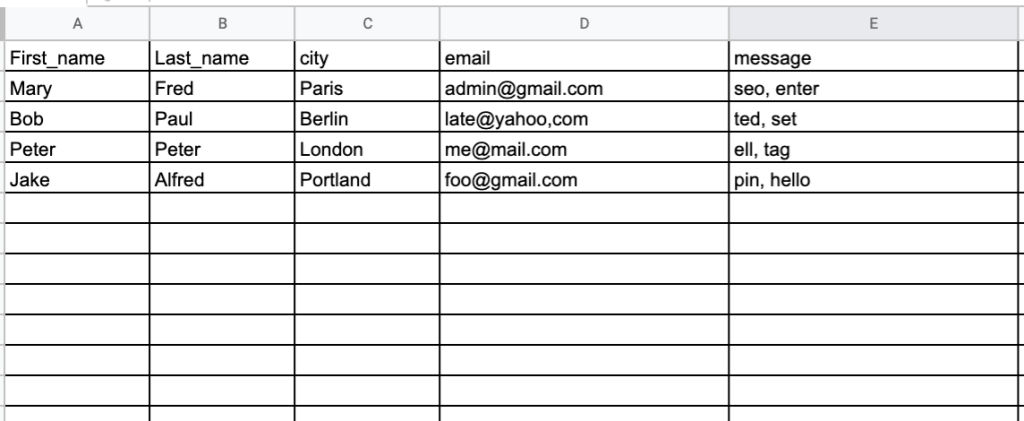
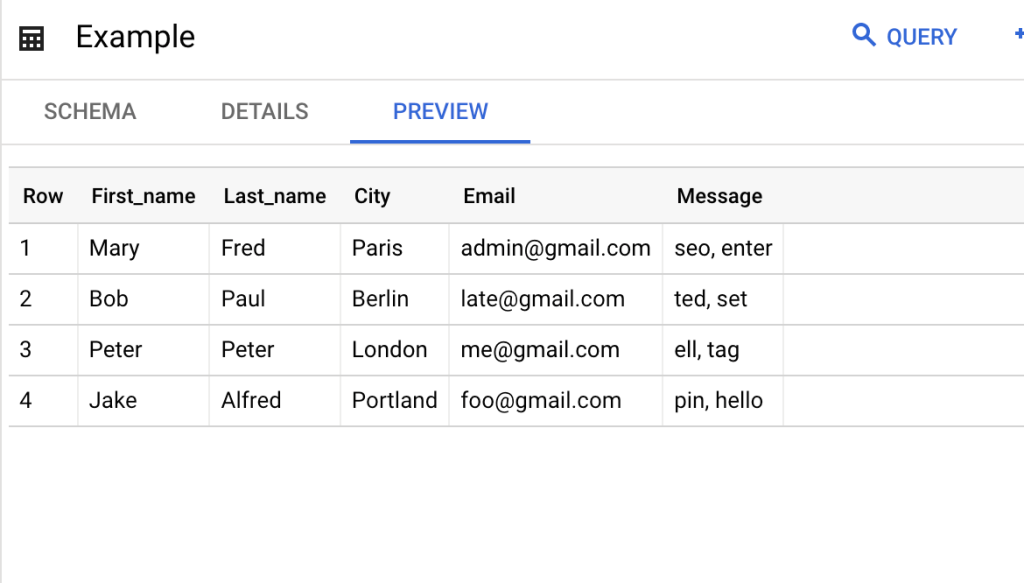
In order to illustrate additional substring examples, we’ll use this random data table imported from Google Sheets to BigQuery using Coupler.io. With Coupler.io, data can be automatically imported into BigQuery, Google Sheets, or Excel from a variety of different sources.

The main advantage here is the ability to set a schedule for data import. Check out integrations with BigQuery to see your favorite software that you can import to BigQuery using Coupler.io.
Here is the dataset in Google Sheets.
And here is how it looks in BigQuery after the import.
To get the substring between two characters, we will use the REGEXP_SUBSTR() function. This function returns the value of the substring that matches the regular expression, or NULL if no match is found.
Note:
REGEXP_SUBST()is the regular expression equivalent ofSUBSTR().
The syntax for this is:
REGEXP_SUBSTR(value, regexp, position, occurrence)value– refers to the string to be searched for.regexp– refers to the regular expression required to find a substring.position– refers to the integer value that specifies the position to start the search. It’s default position is 1.occurrence– (optional) controls the occurrence pattern of the string to return. Defaults to 1.
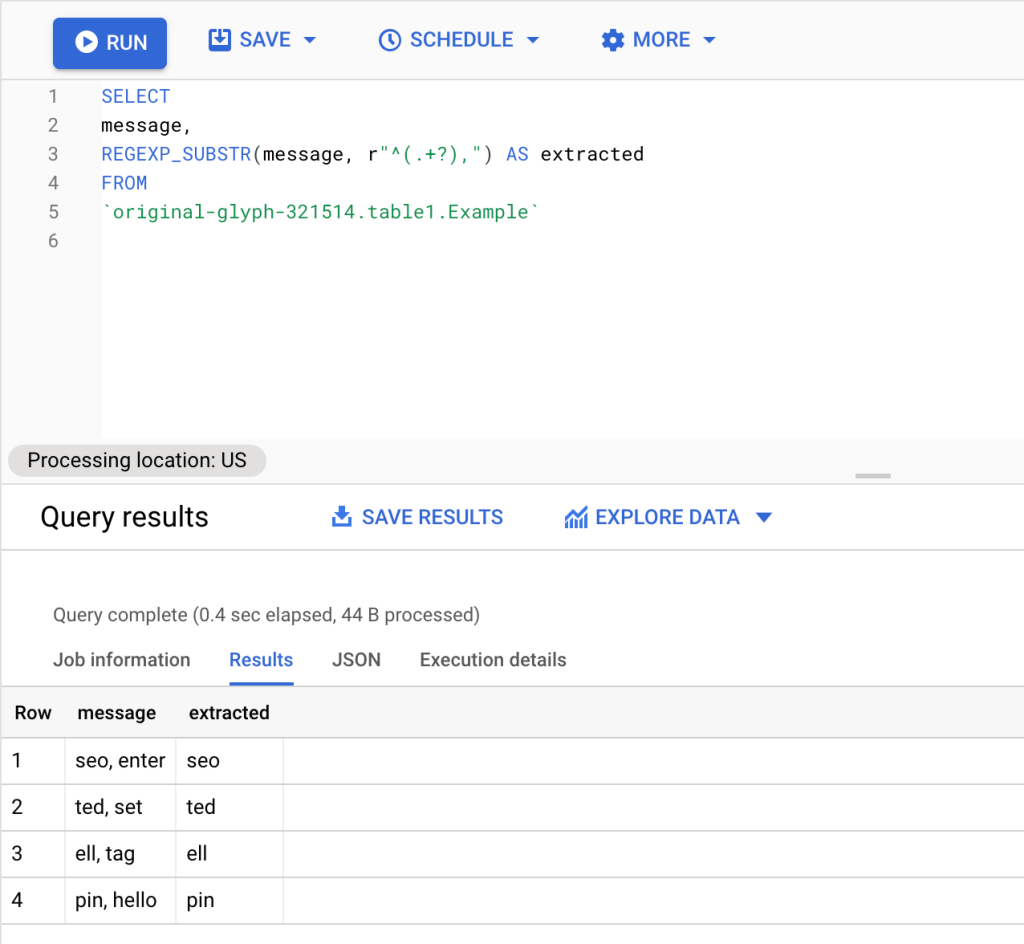
Let’s look at the example using the data from the table above. On the message column, we have two characters separated by a comma. Now we will try to return the value of the substring that matches the regular expression. Using the function REGEXP_SUBSTR and this regular expression ^(.+?), , we extracted everything that appears before the first comma.
SELECT message, REGEXP_SUBSTR(message, r"^(.+?),") AS extracted FROM `original-glyph-321514.table1.Example`
BigQuery substring before character
There are certain situations when we must either identify a substring after or before a specific character in a given statement, depending on the context.
To find a substring before a certain character from the table above we have the email column. Let’s consider this email me@gmail.com. We will extract the substring before @ from this email. The formula for this is:
select REGEXP_SUBSTR('me@gmail', '[^@]+')
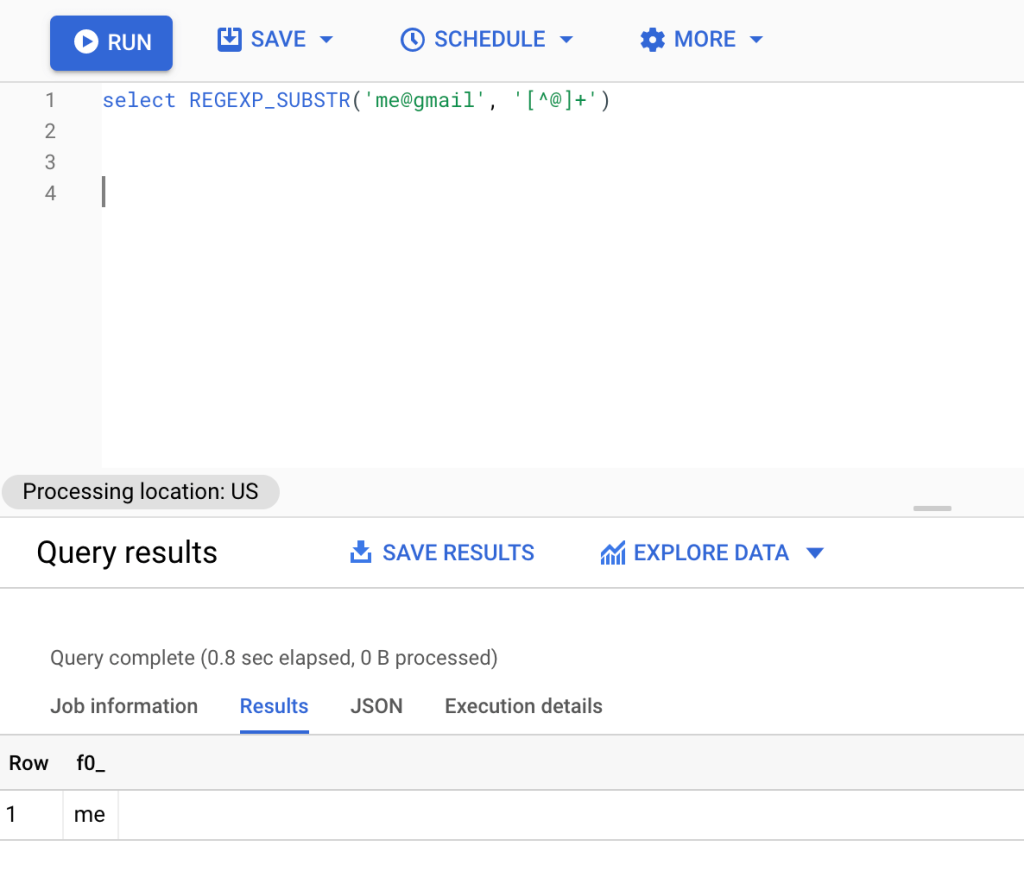
Let’s break down the above query for a better understanding. To begin, we used REGEXP_SUBSTR() to return the value of the substring that matches the regular expression. What we want to do is to extract everything before the @ character. Using this regular expression '[^@]+', we extracted everything before @ from the string.
BigQuery substring after character
Now we are going to extract the substring after the @ character from this email admin@gmail.com from the table above. Here is the formula:
Select
REGEXP_SUBSTR('admin@gmail.com', "@(.*)") AS Example_10
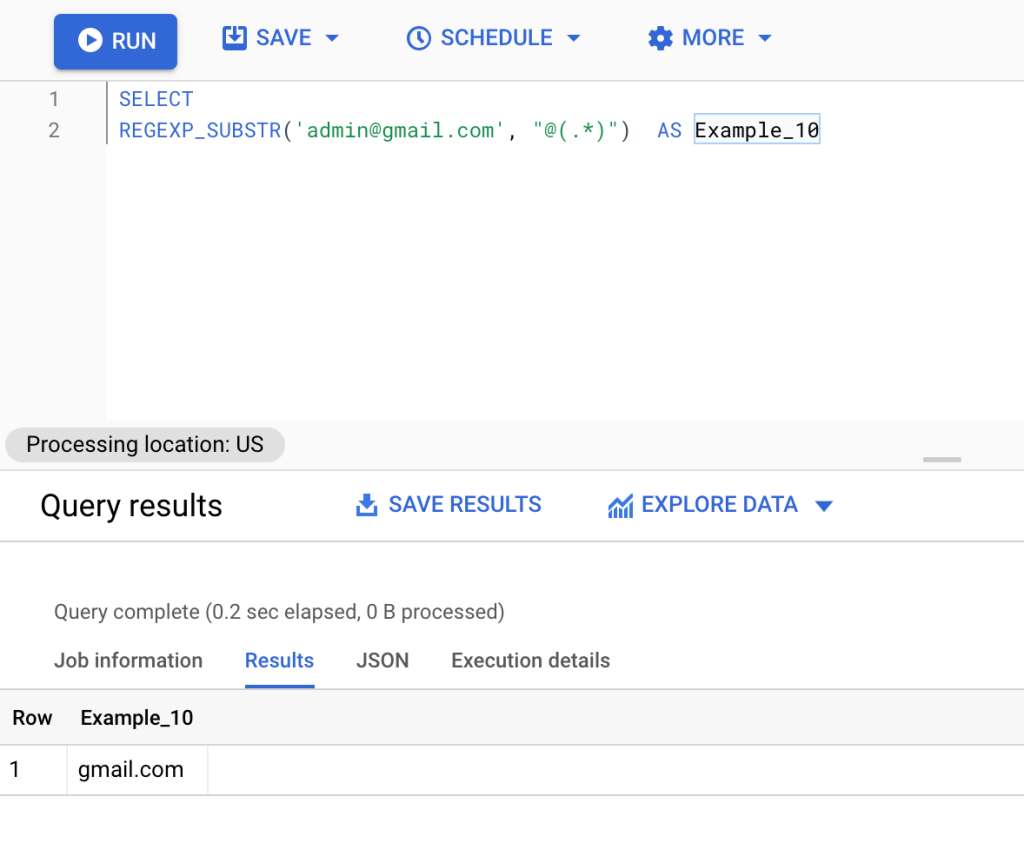
To begin, we used REGEXP_SUBSTR() to return the value of the substring that matches the regular expression. Then we extract everything that comes after @ from the string using this regular expression ????"@(.*)".
Alternatively, we can use SUBSTR with STRPOS to extract the substring after @. The syntax for this is:
SUBSTR(original, STRPOS(original, character)+1)Here is an example:
Select
SUBSTR('admin@gmail.com', STRPOS('admin@gmail.com', '@')+1) AS Example_10
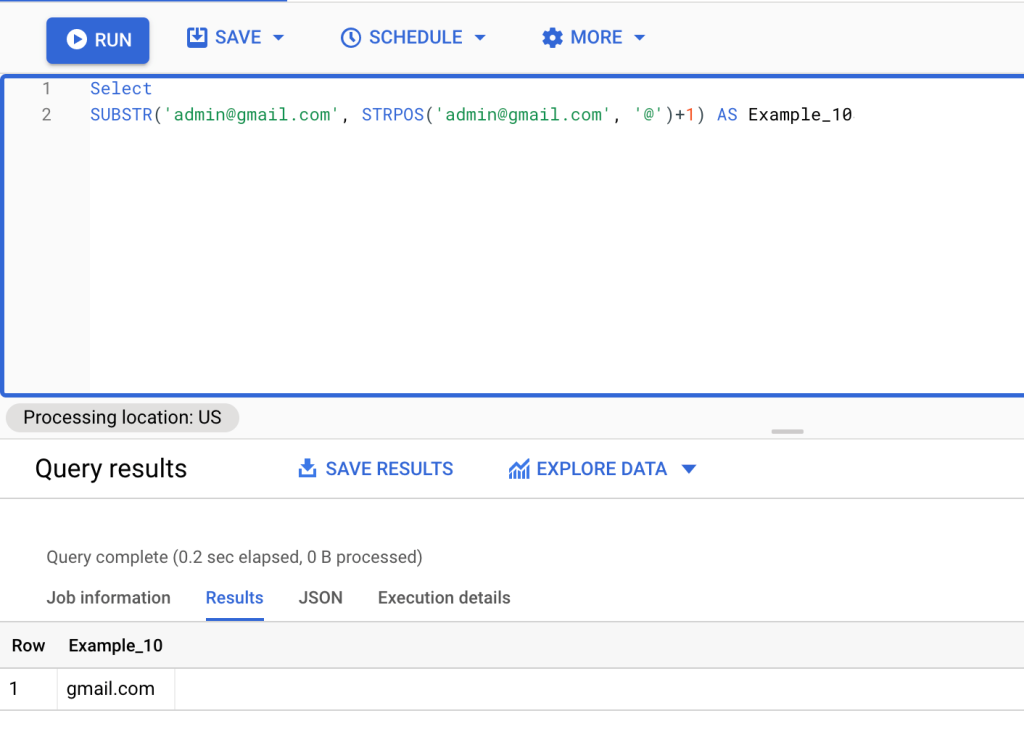
For this, the first step is to use the STRPOS() function inside the SUBSTR() function to define the precise location of the @ character in the string. Afterwards we add 1 to the substring to indicate where the beginning is.
BigQuery replace substring
For the most part when working with data, substrings can be extracted or replaced after you’ve located them. REGEXP REPLACE() is an option for replacing a substring. It replaces all substrings of value that match regular expression with replacements that the string returns. The syntax for this is:
REGEXP_REPLACE(value, regexp, replacement)Let’s look at the formula example using the table from above:
SELECT REGEXP_REPLACE(First_name, 'a|e|i|o|u', 'y') FROM `original-glyph-321514.table1.Example`
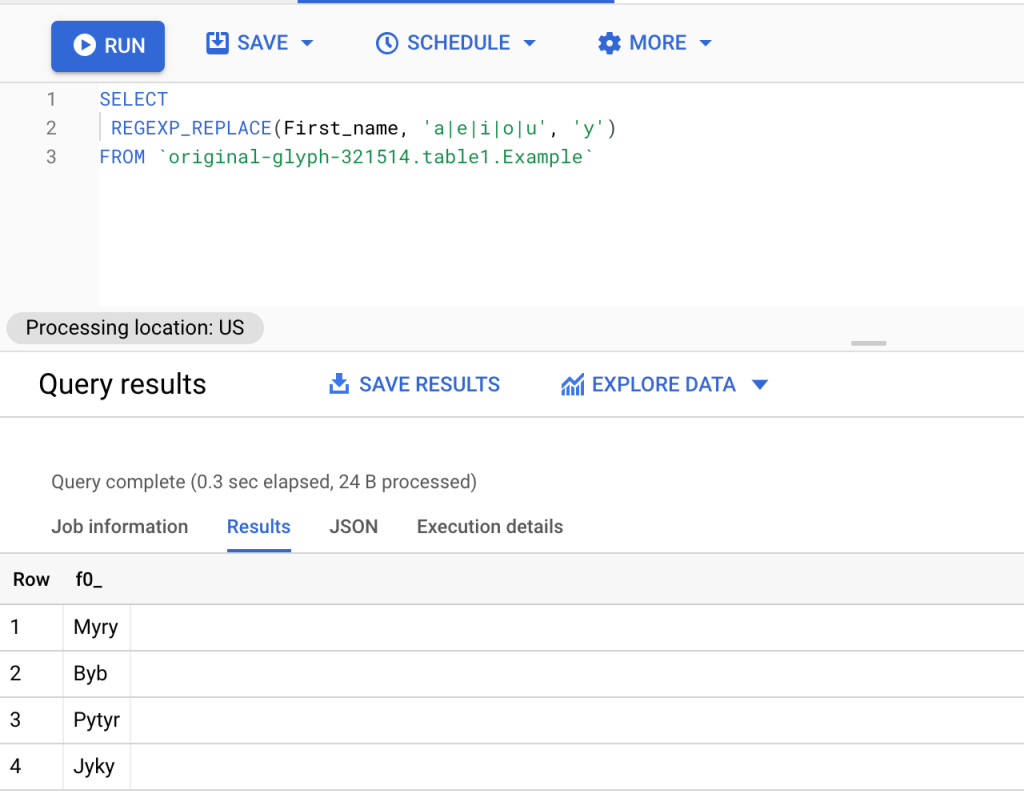
In this example, we are replacing all the vowels (a,e,i,o,u) with y and we are using this | OR pattern.
Note: The REGEXP_REPLACE function will perform a case-sensitive search. Small letters won’t replace capital letters. However, to make search case insensitive, one can use
(?i)before the expression.
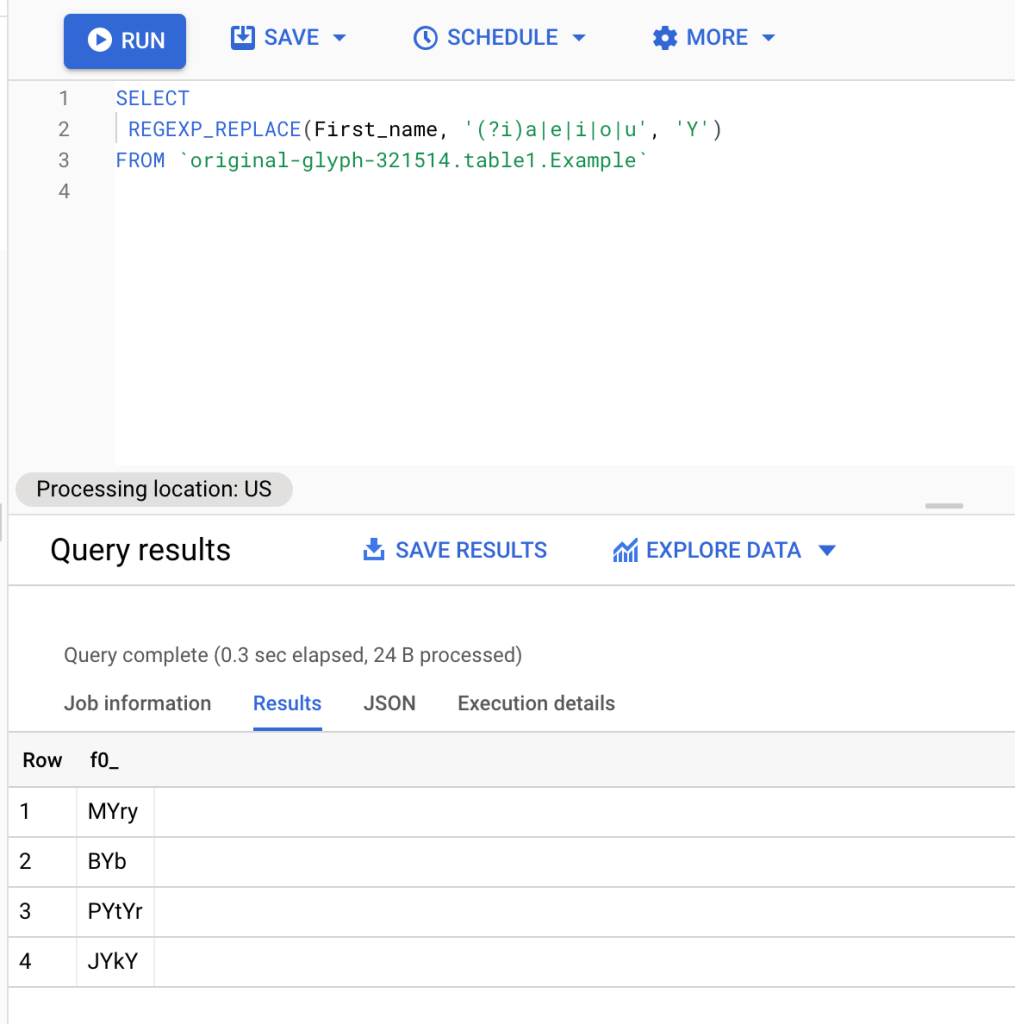
Let’s take a look at this example below, still using the query formula above we will add (?i) to the expression to replace all the vowels (a,e,i,o,u) with Y.
SELECT REGEXP_REPLACE(First_name, '(?i)a|e|i|o|u', 'Y') FROM `original-glyph-321514.table1.Example`
Does BigQuery have ANSI SQL substring
The abbreviation ANSI refers to the American National Standards Institute. To be compatible with the ANSI standard, the query must support at least the main commands, such as SELECT, DELETE, UPDATE, etc.
Numerous approaches exist in Google BigQuery for sorting strings and bytes data types, however, the most often used parameter is the ANSI SQL model BigQuery SUBSTR function. This supports the main commands listed above as well.
BigQuery substring index
In SQL you can do a substring index to return a substring of a string using a delimiter value. Below is the syntax and example.
SUBSTRING_INDEX(str,delimiter,n)Example:
SELECT SUBSTRING_INDEX("coupler.io", ".", 1);
This returns Coupler
However, in Google BigQuery we use SPLIT(). The SPLIT function separates the substring value using the delimiter argument. The following is the syntax for this:
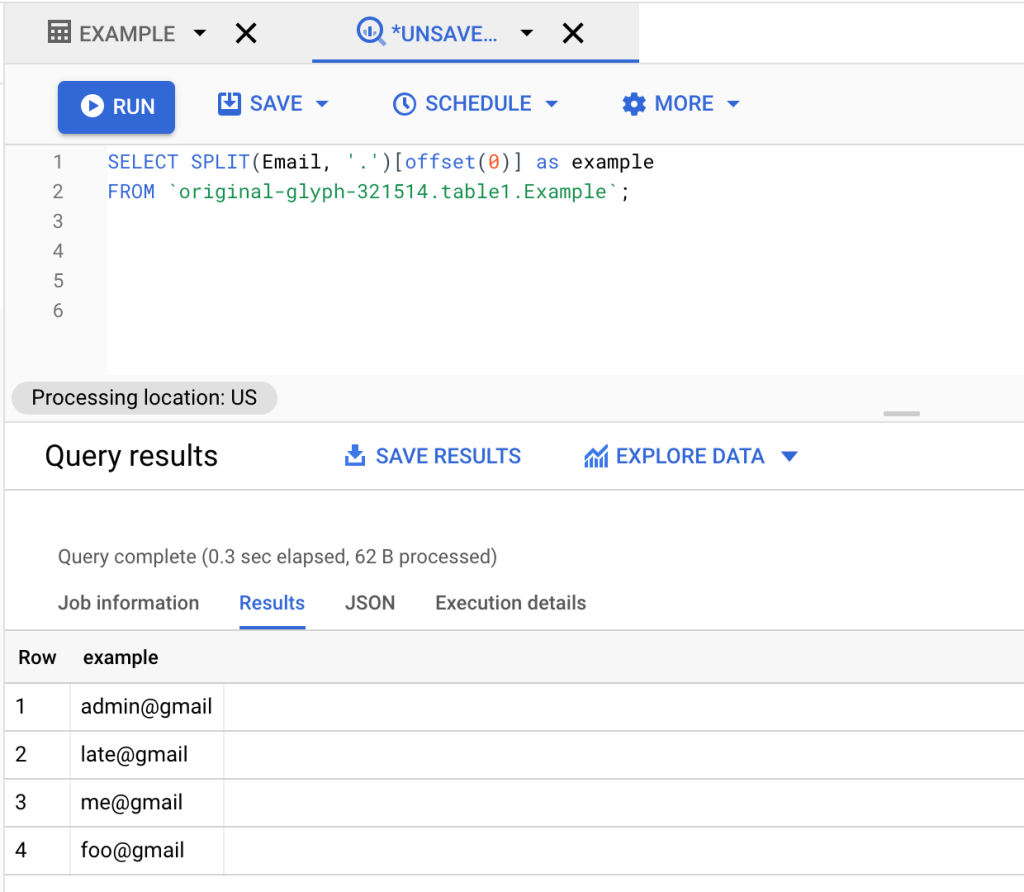
SPLIT(value, [delimiter])Let’s take a look at the example, where we split emails using the . delimiter into two separate parts. We then added an offset of 0 in order to retrieve just the first part:
SELECT SPLIT(Email, '.')[OFFSET(0)] AS example FROM `original-glyph-321514.table1.Example`;
BigQuery substring recap
Throughout this post, we’ve used a combination of graphical representations and real-world examples to highlight the many ways that substrings may be used in BigQuery.
I hope that this article has been useful and serves as a guide to help you choose the most appropriate option when working with strings in the future. If you still have a problem working with substrings? Leave a comment in the section below!
