Companies use different tools to store their operational data. For example, development teams use Jira, UX designers – Figma, marketers – Google Analytics, and so on. To make the data accessible for reporting, analytics, and machine learning models, it should be stored in a single place or repository. For this, you need to extract data from the sources, transform the data into a unified format, and load it into your database. This is what the ETL process actually looks like.
What is ETL
ETL is an automated process of integrating data from multiple sources into a central repository, such as a database or a data warehouse. It includes three steps which, if you look at their first letters, explain the ETL meaning well:
- Extraction
- Transformation
- Loading
Being an integral element of business intelligence systems, ETL automates the process of data transfer from source to destination and contributes to discovering valuable business insights.
Benefits and challenges of ETL
| Benefits | Challenges |
| Dataflow automation | Data latency |
| Improved maintenance and traceability | Data source limitations |
| Enhanced performance to BI | Data validation |
| Improved data quality | Resources for implementing ETL |
| Information clarity and completeness | Data corruption due to ETL pipeline errors |
The more spread the data is across different apps, the harder it is to get the big picture of the business. Having a reliable, automated ETL solution can have a paramount impact on an organization’s ability to understand its own data and make informed decisions. At the same time, automations save time and help avoid common errors that typically arise when data is moved manually between different apps or locations.
And once you have an ETL process sorted out, you’re bound to see some positive outcomes for your organization. It could mean, for example, retaining more customers as Tradezella did. For others, organizing their data can open up opportunities for revenue growth, as was the case for Mailtrap.
ETL and data integration
In view of the above, you may have a concern about what’s the difference between an ETL process and a data integration process. Both concepts are closely related, and, as a matter of fact, Extract Transform Load is an approach to data integration.
The main difference is that data integration does not involve transforming data to provide you with a unified view of your data taken from multiple sources. The Extract Transform Load process changes the format of information at the transformation step.
You may need to know what the difference is between both terms to make a proper choice.
ETL and reporting
These two concepts are complementary to each other within business intelligence:
- An ETL process is responsible for collecting information from data sources and transferring it into one repository.
- A reporting process is responsible for accessing the information in the repository and presenting it to the stakeholders in a legible format, such as a dashboard.
Each concept can exist separately from another. However, if you use a bundle of ETL + reporting, you can benefit from their synergy in terms of automating reporting and speeding up the decision-making.

Streamline your data analytics & reporting with Coupler.io!
Coupler.io is an all-in-one data analytics and automation platform designed to close the gap between getting data and using its full potential. Gather, transform, understand, and act on data to make better decisions and drive your business forward!
- Save hours of your time on data analytics by integrating business applications with data warehouses, data visualization tools, or spreadsheets. Enjoy 700+ available integrations!
- Preview, transform, and filter your data before sending it to the destination. Get excited about how easy data analytics can be.
- Access data that is always up to date by enabling refreshing data on a schedule as often as every 15 minutes.
- Visualize your data by loading it to BI tools or exporting it directly to Looker Studio. Making data-driven decisions has never been easier.
- Easily track and improve your business metrics by creating live dashboards on your own or with the help of our experts.
Try Coupler.io today for free and join 1M+ happy users to accelerate growth with data-driven decisions.
Start for freeHow ETL works
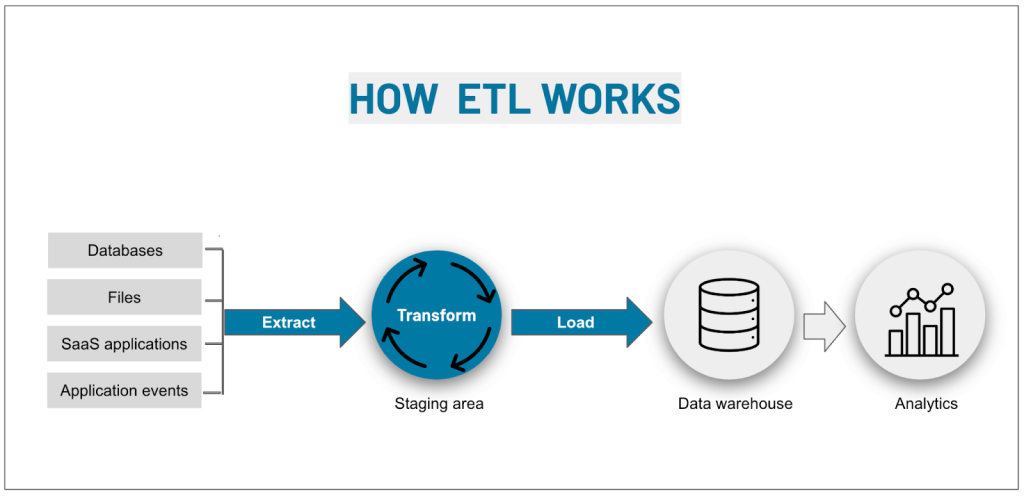
To automate data import from different sources into one database, you’ll need to implement an Extract Transform Load process, which covers the following steps:
E – Extraction of data
At the first step of the ETL process, the data is extracted from a source or an array of sources onto a staging server. The sources from which the data is extracted can include:
- Databases and data warehouses (Airtable, BigQuery)
- Cloud storage (Google Drive, OneDrive)
- E-commerce platforms (Shopify, WooCommerce)
- Analytics services (Google Analytics, Mixpanel)
- Project management tools (Trello, Jira)
- CRM tools (Pipedrive, HubSpot)
- And many more
T – Transformation of data
The extracted data is checked against a series of validation rules that transform data before loading it into the central repository. These rules may include:
- Conversion to a single format
- Sorting and/or ordering
- Cleansing
- Pivoting
- Standardization
- Deduplication
- and many more.
L – Loading of data
The transformed data is loaded into the destination (data warehouse, data lake, or another repository) in batches or all at once, depending on your needs.
What is an ETL pipeline
An Extract Transform Load pipeline is a kind of data pipeline in which data is extracted, transformed, and loaded to the output destination. ETL pipelines typically work in batches, i.e., one big chunk of data comes through ETL steps on a particular schedule, for example, every hour.
ETL technology – example
Let’s take a look at a simple ETL pipeline in real life. A small e-commerce business uses different tools in its operational activities – some for tracking sales, others to run marketing, accounting, logistics, and more. They chose to employ an ETL platform – Coupler.io in this case – to get all their data into one place and analyze it. They hope to understand better where their business is at the moment and make future decisions in a data-driven way.
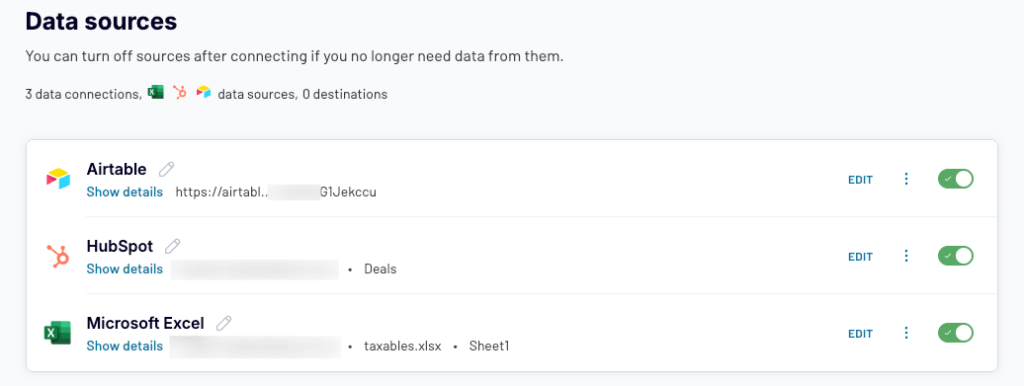
Sales data of this e-commerce company is spread between HubSpot and Airtable, with some historical data residing also in an Excel file.
Explore other ETL use cases for marketing, sales, ecommerce, and finance.
Their first step will be extracting all the relevant data from all three sources. As you can guess, this is the E (Extract) in ETL. Using Coupler.io, one of the best ETL tools, they connect to each tool and decide what to fetch. Here’s a sample setup:
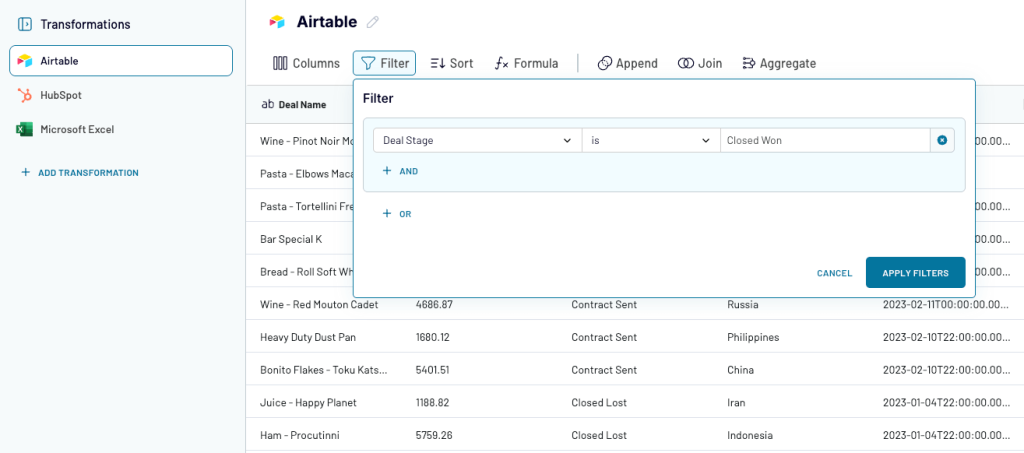
Next, they aim to Transform the data. Rarely, the raw data exported from apps is ready for analysis right from the get-go. Much more often, you need to pick the columns you need for your analysis, apply filters, perform some calculations to derive new metrics, etc. As one of the leading data blending tools, Coupler.io also enables users to unify data from multiple sources into a single dataset. So our e-commerce company gladly takes their time preparing its data for analysis.
Finally, it’s time to load the processed data. There are several options here. With Coupler.io, you can load data to a spreadsheet app (Excel, Google Sheets), a data warehouse (BigQuery, RedShift), or directly into a data visualization tool (Looker Studio, Power BI, Tableau). The company we discuss chooses a Google Sheets file where the data is quickly brought.
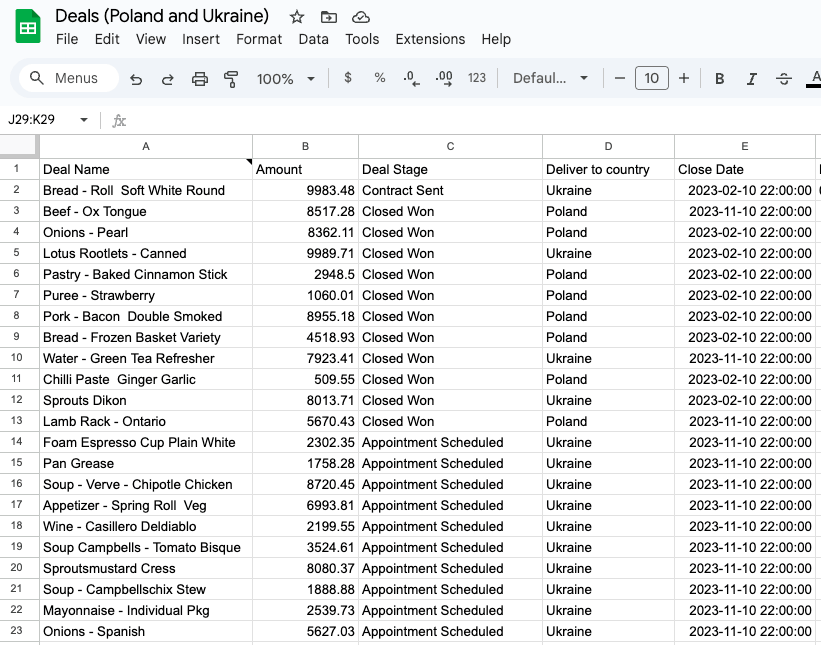
Once set up, an ETL process will run automatically according to a schedule they choose, for example, daily.
Coupler.io supports over 400 data sources, with more and more coming soon. You can give it a try on a free 7-day trial, no credit card is required. Here are some of the popular integrations available:
- Airtable to Google Sheets
- WordPress to Google Sheets
- Hubspot to Google Sheets
- Xero to Google Sheets
- CSV to Google Sheets
- Shopify to Google Sheets
How to manage an ETL process
If you’re planning to build a custom ETL pipeline from scratch, you’ll have to handle a lot of tasks, such as:
- ETL process management
- Outline the Extract – Transform – Load process and provide system architecture for the entire pipeline
- Manage the development of the system and document its requirements
- Data modeling
- Define data formats (models) required for the data warehouse
- Outline the transformation stage
- Define technologies and solutions to implement formatting
- Testing
- Data warehouse architecture
- Define data warehouse architecture (data marts, accessibility, queries, metadata, etc.)
- Define tools and solutions to load data
- Testing
- ETL pipeline development
- Implement ETL tools to extract data from sources and upload it to the staging area
- Set up the data formatting processes, such as cleansing, mapping, filtering, etc.
- Implement the process of loading the formatted data to the data warehouse
- Validate data flow
- Test speed
You’ll need an ETL developer or a data engineering team to build and maintain the ETL infrastructure. The team may include data architects, engineers, analysts, scientists, and other dedicated experts who will manage the ETL process.
However, small to medium business owners do not need to carry such a burden of tasks. They can benefit from preset solutions with ready-to-go integrations between data sources and data destinations. So, they won’t have much trouble with setting up their ETL pipeline.
ETL future development
The traditional Extract Transform Load concept is a good solution for relational processing. However, its main limitation should be taken into account:
When the data volume goes up – the ETL performance goes down.
In view of this, some data analysts forecast the future transformation of ETL into ELT pipelines. The Extract Load Transform (ELT) approach lets you get your data as-is and manipulate it immediately. This is beneficial for unstructured or semi-structured information and lets you start getting value from it immediately.
ELT basically turns the ETL concept around. Instead of transforming the data prior to loading, it first loads the extracted data, and only then transforms it. It eliminates the need for the staging area and the bottleneck that it can create in your system.
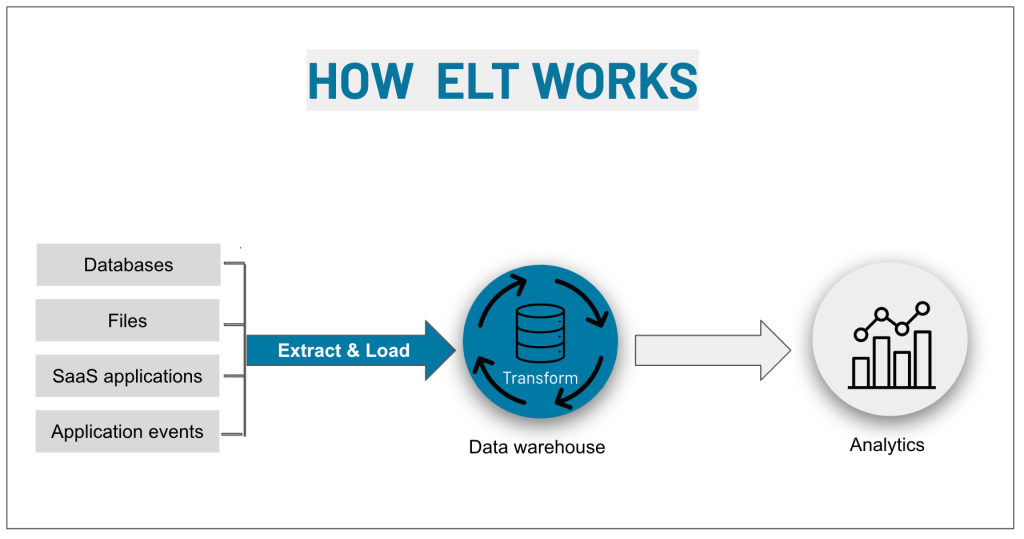
At the same time, the more obvious scenario of ETL evolution includes the advent of data management frameworks. This means that traditional ETL will combine data integration with data management. So, the users will have an out-of-the-box hybrid solution to streamline their ETL pipelines and simplify data analytics.
ETL vs ELT
What should you choose for your organization? See the following table to find the key information and differences between the both approaches. Check out the next sections to learn more about each of them
| ETL | ELT | |
|---|---|---|
| Data is first transformed and then loaded into the data storage solution | Working order | Data is loaded into the data storage solution and then transformed |
| Highly developed technology | Ease of adoption | New technology, may require more investment to adopt |
| Requires a staging area outside of the warehouse | Data transformation | Happens within the warehouse or a lake |
| Can be used to transform unstructured data and load it into structured form | Support of unstructured data | Can be used to store unstructured data |
| Slow | Data loading speed | Fast |
| Initially takes longer, but later on, analysis becomes faster | Data transformation speed | Can be faster since you can run smaller queries on the raw data |
| Best for on-premise data warehouses. | Data storage | Best for data lakes, lakehouses, or marts. Works well with cloud-based storage as well. |
| Low | Storage size | High |
| Structured data | Source data | Structured, unstructured, or semi-structured data |
| Best suited for small amounts of data | Amounts of data | Works well with large data pools |
| Only transformations selected by the user are available | Availability of data | All raw data is available |
| High | Latency | Low |
| Low | Flexibility | High |
| Low | Scalability | High |
| Legacy on-site solutions require expensive maintenance | Maintenance | Cloud-based solutions do not require maintenance |
| Can be extremely costly upfront if you’re using an on-site solution. Cloud-based solutions are much cheaper. | Cost | The initial cost for loading data is low, but most cloud-based solutions charge per query. Running large queries may be very expensive. |
The most significant advantages of these technologies are clearly identified by Aly Hussein, Data Consultant:
In ETL, heavy transformations are done before loading, so the data that lands in the warehouse is already clean, validated, and shaped to a strict schema.
In ELT, raw data is loaded first and can be transformed directly inside the warehouse. This avoids extra data movement and leverages the warehouse’s own compute for faster ingestion and better scalability.
ETL vs ELT pros and cons
Even though ELT is the newer development in data science, it doesn’t mean it’s better by default. Both systems have their advantages and disadvantages. So let’s take a look before going deeper into how they can be implemented.
ETL pros:
1. Fast analytics
While transforming data prior to loading it into your storage solution can be a rather slow process, it does come with its advantages. Since the data is already pre-structured when it’s loaded, analyzing it is fast and straightforward.
2. Safety compliance
Another benefit is compliance with safety protocols, especially GDPR. When using ELT, you inevitably load raw data that can reveal your customers. This can include email addresses or IP addresses that must be masked as per the EU guidelines. If your storage is based outside of the EU, you’ll be breaking the law by uploading this type of data without transformation.
With ETL, this problem is non-existent as you transform the data prior to loading and do not include sensitive pieces of data.
3. Low storage requirements
When it comes to data storage, ETL also has a great benefit. As you’re not storing large amounts of raw data, you don’t need as much storage capacity. This is cost-effective if the storage solution you use charges for storage.
4. Wide adoption
The last of the major benefits of ETL is the fact that it’s been out there for over twenty years. As a result, there’s a lot of infrastructure and tools surrounding it. So, you will have little to no problems implementing it in your organization.
ETL cons:
1. Initial cost
One of the most obvious disadvantages of ETL is the high initial cost. The cost will be measured in hundreds of thousands of dollars if you plan to have on-site data storage. Even if your storage is cloud-based, the initial cost is going to be rather high because you need to start with creating a transformation algorithm. With ELT, you can start uploading data and then run small transformations before settling on an advanced custom solution.
2. Lack of flexibility
ETL isn’t as flexible as ELT. Since you need to have a large transformation algorithm that needs to export data and transform it prior to loading, it would take a lot of work to change it. If you’re changing data sources or need to add a new one, this could mean rewriting parts of the large algorithm, and dealing with legacy is never easy.
3. Slow processing
A minor but an important drawback is that working with large amounts of data becomes increasingly difficult with ETL. The transformation stage may become a bottleneck in the system and cause it to process the data slower.
ELT pros:
1. Fast loading
One of the main advantages of ELT, as opposed to ETL, is a much faster processing speed when dealing with Big Data. A BigQuery or Amazon Redshift pipeline will load all your raw data much faster than any ETL solution would.
2. Lots of analytics options
Since you’re storing large amounts of raw data, ELT is ideal for broad scope analytics. You can both run very limited transformations to get reports about specific things, or a large analysis of historical data. ETL doesn’t allow this as it doesn’t store raw data.
3. Low maintenance requirements
Maintenance will be out of the picture with most ELT systems as you won’t have to use on-site storage, and companies that offer ELT services do all the maintenance themselves.
ELT cons:
1. Hard to implement
The price for that ease of maintenance is that setting up an ELT pipeline can be hard and expensive. In addition, it’s a relatively new technology and finding an employee or a contractor who possesses a high level of expertise can be a challenge.
2. Price per query
Running such a system can also incur a high cost on your business. Most ELT tools charge business owners for each query depending on the amount of data being transformed. With larger queries, it can be rather expensive and smaller businesses may not have the resources to be running analytics constantly.
When to use ETL or ELT?
Every company and organization is different. If you want to decide whether you want to use ETL or ELT at yours, refer to this section.
Aly Hussein, Data Consultant, suggests:
Use ETL when strict data quality, rigid schemas, or significant pre-storage cleanup is required (e.g., finance, compliance, legacy data warehouses).
Use ELT when working with modern cloud platforms (Snowflake, BigQuery, Databricks) and you need fast loading, scalable in-warehouse transformations, and flexibility for large or semi-structured data.
ETL use cases
Typical ETL use cases include automating the reporting process, collecting customer data or marketing data for analysis, integrating financial data from different data sources, and so on.
When you need ETL – checklist:
- Your company has its own storage
- Data storage cost is crucial
- You’re working with small to medium amounts of data
- Your data is consistent
- You need standard analytics
ELT use cases
The most typical use cases would be big data processing, storing large datasets to track historical changes, and integrating data from multiple sources for various data science tasks.
When you need ELT – checklist:
- You deal with a lot of data
- Data needs fast storage
- You need historical data analysis
- Data sources change often
- You run different types of analytics
- Have the resources to process
Do I need an Extract Transform Load process for my project?
You tell us 🙂 If you leverage multiple tools in your workflow and spend hours grabbing data from them manually, then you MUST implement an ETL pipeline. This will save you tons of time and, I believe, budget.
No business can survive without a proper analysis of data taken from different sources. Analyzing data is crucial, and the best way to do this is when you have all your data in one place. Good luck!
