Data extraction, data export, data integration, data mining…all these concepts are buzzwords for businesses that need to process big data. The efficiency of implementing each of these processes clearly defines your business health in the long run. Decision-making driven by data is no longer a trend but a requirement to move forward and leave your competitors behind.
In this text, we’re talking about data extraction, which is the essential process of collecting data and the pioneering step in ETL. The focus will be on disclosing the value of data extraction for business needs and some insights into best practices. Read on.
What is data extraction?
Data extraction is the process of retrieving raw data from a single source or different sources and replicating it in a desired destination. Sources for data extraction may include web apps, databases, files, cloud-based software, and more. The destination for the extracted data usually includes spreadsheets, databases, or data warehouses.
For example, you have ad campaign data in Facebook Ads. You want to extract information from this platform into Microsoft Excel to share it or build a report.
The role of data extraction in ETL
Data extraction is a part of a bigger concept known as ETL (Extract, Transform, and Load). ETL or ELT is the process of creating a centralized database consisting of three steps:
- Extraction of data from a source
- Transformation of data into the required format
- Loading data into the destination

The role of data extraction in ETL is crucial since it feeds the data. After that the data will be transformed which can include the removal of duplicates or irrelevant data, data conversion data into a common format, data consolidation from multiple sources into a single dataset, and more.
Sometimes, ETL data extraction can be the most time-consuming stage of the entire ETL p[rocess, especially if you extract large volumes of unstructured or semi-structured data from multiple sources. The quality of the extracted data also matters since it affects the accuracy and efficiency of the uplocing stages of the ETL process.
How to extract data: manual or automated data extraction process
You can extract data manually or automate the process using a tool or a custom solution. An example of manual data extraction can be the export of data from Facebook Ads manager as CSV. As a result of the export, a CSV file with raw data will be downloaded to your computer. Another example is when you manually run SQL queries to extract data from a BigQuery table.
Alternatively, you can automate data extraction with Coupler.io. It provides data connectors to get your data exported from the chosen source to the chosen destination on a schedule. Some ETL data extraction tools allow you to only retrieve the updated records by comparing source and destination systems, the so-called incremental data extraction. We’ll talk more about it in the next section.
Manual data extraction is often time-consuming and prone to errors. However, if it’s impossible to automate data extraction from a specific source, you have to do this manually. Sure thing, the automated method is faster and can process bigger volumes of data. Data extraction automation also mitigates the risk of bias, ensuring that the data is extracted accurately and in a consistent format.
Two main types of data extraction
Conceptually, ETL data extraction envisages two types that originate from the data to collect: structured or unstructured.
Extraction of structured data
Structured data is the information organized into a formatted repository with a defined data model, structure, and consistent order. Given this, structured data is ready for analysis already after being extracted. In addition to that, the extraction of structured data includes two subtypes: full and incremental extraction.
Full data extraction
This type of data extraction means that the information is obtained entirely from the source to the destination at once.
Incremental data extraction (batch processing)
Incremental data extraction means that the data is being extracted in batches over time instead of the entire dataset at once. Batch processing provides a more manageable way for data extraction and can help reduce the strain on computing resources. The entire set of data doesn’t have to be processed each time a change is made. This reduces costs and saves time.
Incremental data extraction in ETL works by comparing the source and target systems and only extracting the data that has changed. It’s crucial to determine what changes were made to avoid the repeated extraction of entire data. Change data capture (CDC) is responsible for this. It’s a process that captures changes in source systems and applies them to target systems. In a nutshell, CDC catches any changes in the data set from the moment it has been loaded. These changes include new rows being inserted, existing rows being updated or removed. CDC makes for an effective method of keeping the target systems’ data fresh without reloading the whole data set.
Extraction of unstructured data
Unstructured data represents information that isn’t arranged based on a traditional, preset data model. This type of data cannot be stored in a relational database and hence it’s difficult to query it. You can encounter unstructured data in the examples of web pages, emails, survey responses, PDF files, social media posts, and so on.
It’s quite a challenge to extract and process unstructured data. The next step is to prepare data for analysis, which may include duplicate removal or, on the contrary, filling in missing values.
Also learn about sampling data in our blog post.
A few data extraction examples and use cases
ETL data extraction can be useful for different cases, including business intelligence, marketing, and financial analytics, fraud detection, etc. Let’s check out a common use case of using data extraction in a business intelligence process.
A marketing manager needs to analyze the performance of advertising campaigns run across multiple platforms, including Google, Facebook, and LinkedIn. To perform the analysis, the manager needs to extract data entries from all these platforms and combine them into a single data source using a data blending software.
With the help of an ETL data extraction tool, such as Coupler.io, the manager extracts the ads data and loads it into a data warehouse, Google BigQuery. The extracted data can be transformed for further visualization and analysis using business intelligence tools such as Looker Studio, Tableau, or Power BI. Here is the result:
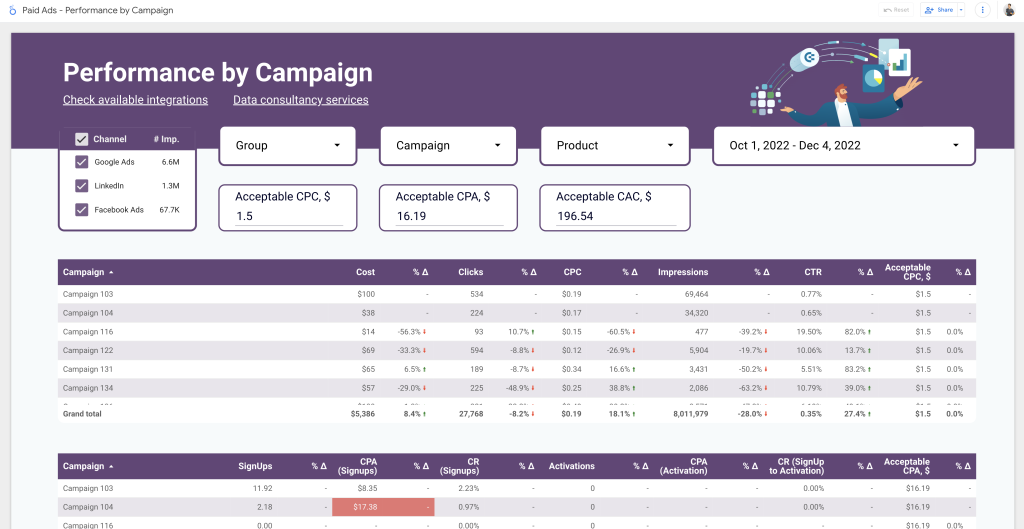
The insights gained from the analysis can streamline business decisions to optimize the performance of advertising campaigns.
This is just one use case for data extraction in business intelligence among multiple others:
- Marketing analytics – you can gain insights into customer behavior and preferences by extracting data from different marketing sources including social media, website analytics, CRM apps, and more.
- Supply chain management – you can manage your supply chain effectively by extracting data from sources associated with suppliers, logistics providers, and other partners.
- Financial analysis – you can analyze financial performance and make data-driven decisions by extracting financial data from accounting systems, financial software, etc.
- Health sciences & analytics – you can improve patient outcomes and analyze healthcare information by extracting patient data from electronic health records, medical devices, and other sources.
- Fraud detection – you can detect fraudulent activity and prevent financial losses by analyzing data extracted from transaction logs and other relevant sources.
XML data extraction example
We borrowed this data extraction example from our XML to Google Sheets guide.
Let’s say you need to extract an XML table from a web page to Google Sheets.
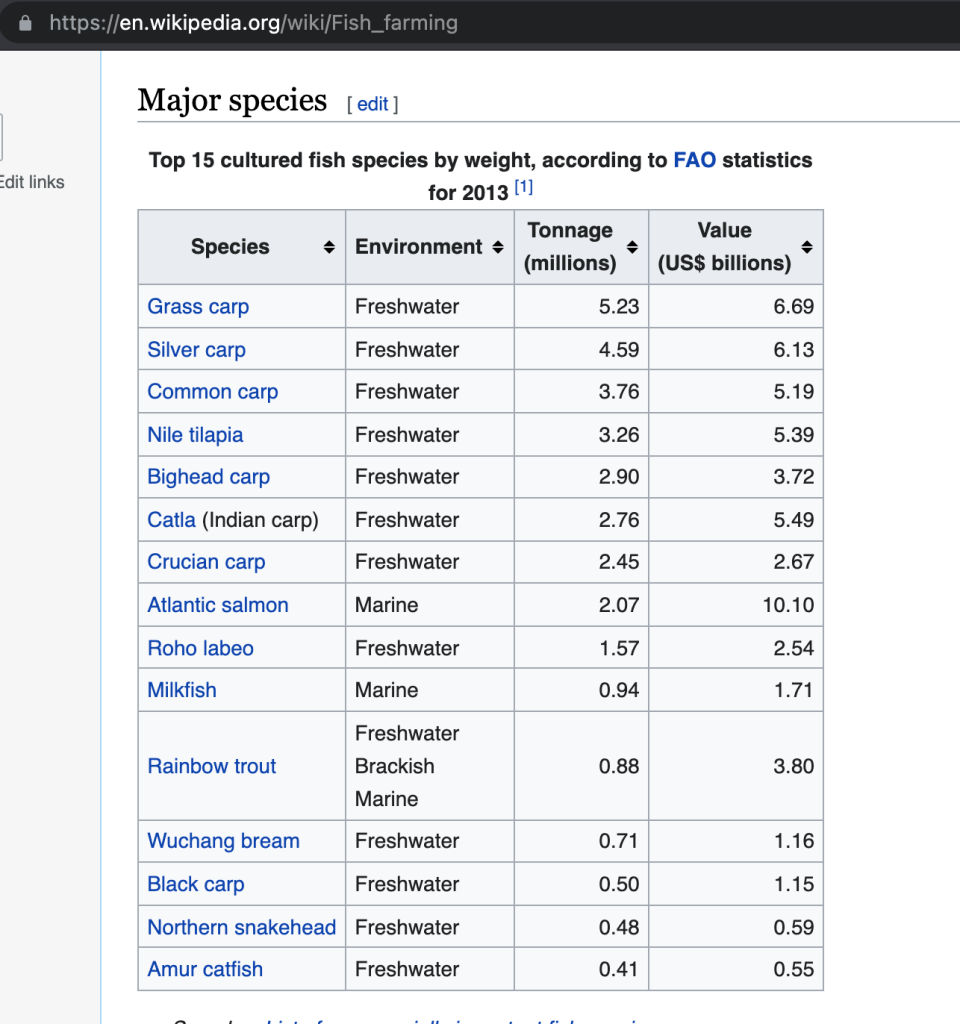
You can do this using the built-in IMPORTXML function, which has the following syntax
=IMPORTXML("url", "xpath_query")
You’ll need to get
- Web page’s URL. Copy it from the search bar of your browser.
- XPath query. Right-click on the table and select Inspect.
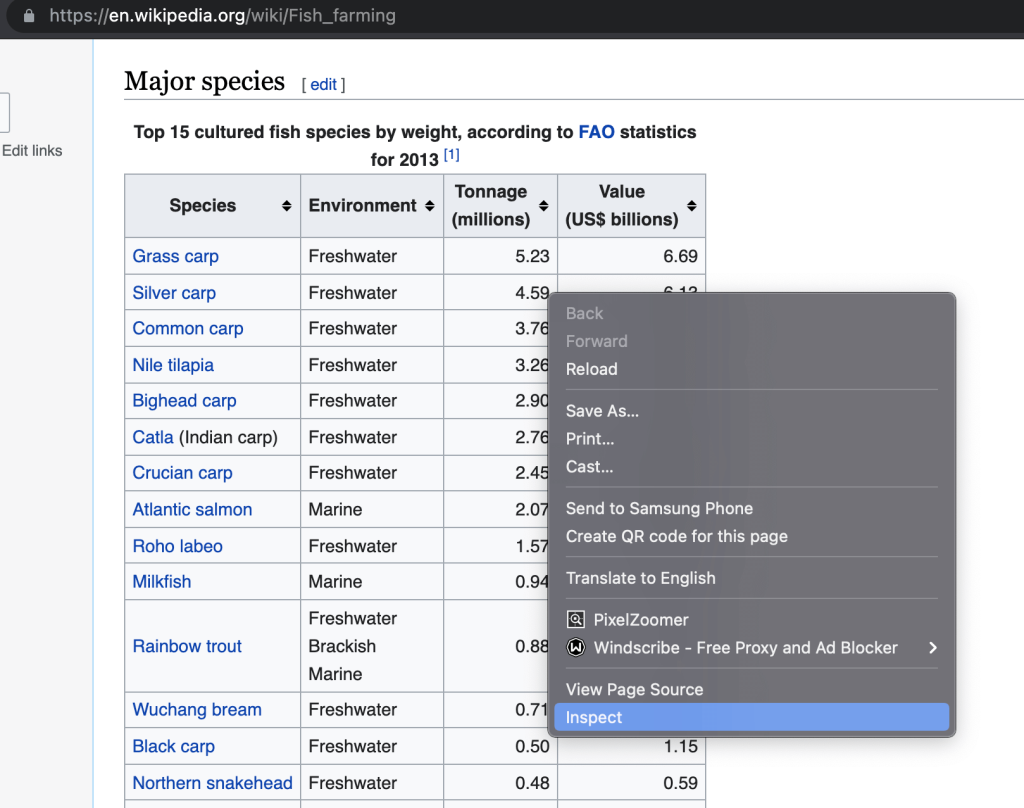
This will open the source code. You can then see how your data is tagged. If it’s displayed in a table, for instance, you’ll see it tagged as <tr></tr>.
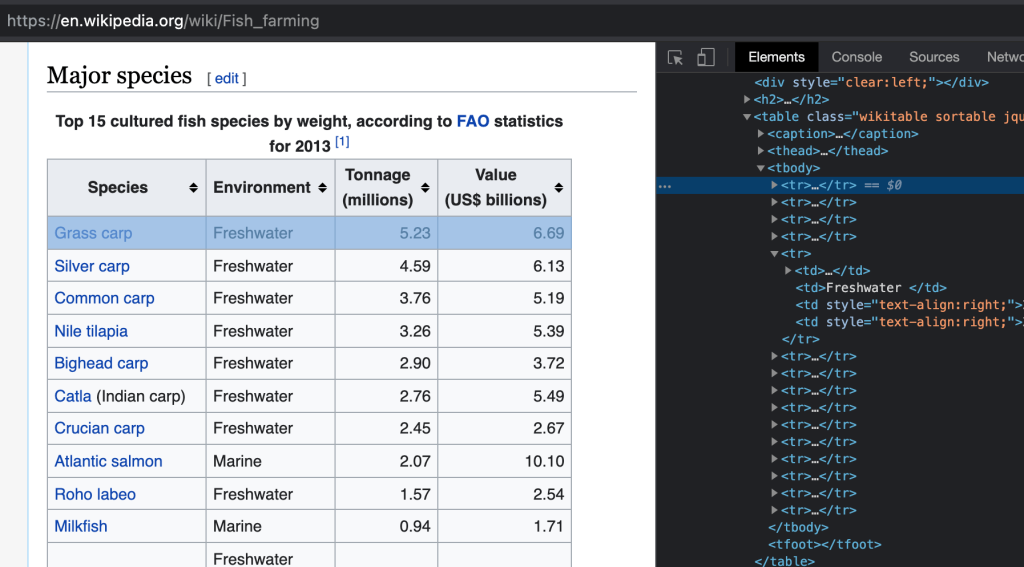
To grab the entire table, we need to use the //tr string. The final IMPORTXML formula will look like this:
=IMPORTXML("https://en.wikipedia.org/wiki/Fish_farming", "//tr")
And here is the data extracted from the web page to Google Sheets.
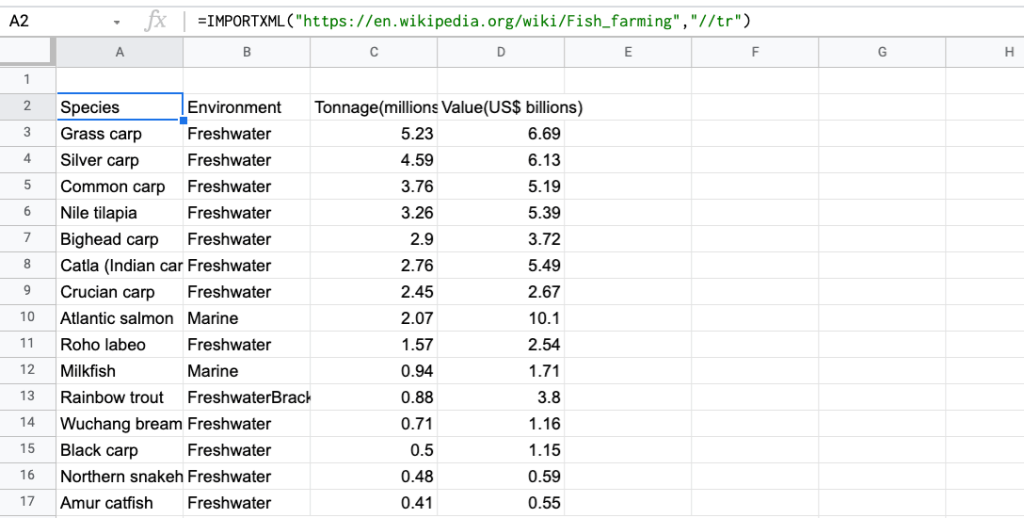
Example of data extraction using a data extractor
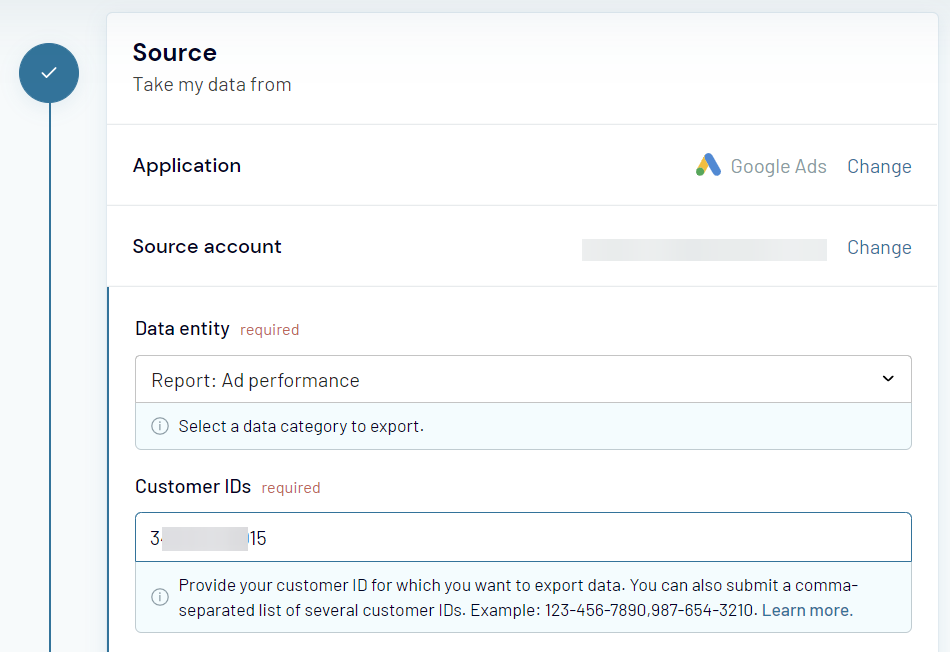
Here is an example of a data connector by Coupler.io that extracts information from Google Ads to BigQuery:
- Sign up to Coupler.io and create a new importer by selecting Google Ads as a source and BigQuery as a destination.
- Connect your Google account with access to Google Ads and select the data you want to extract.
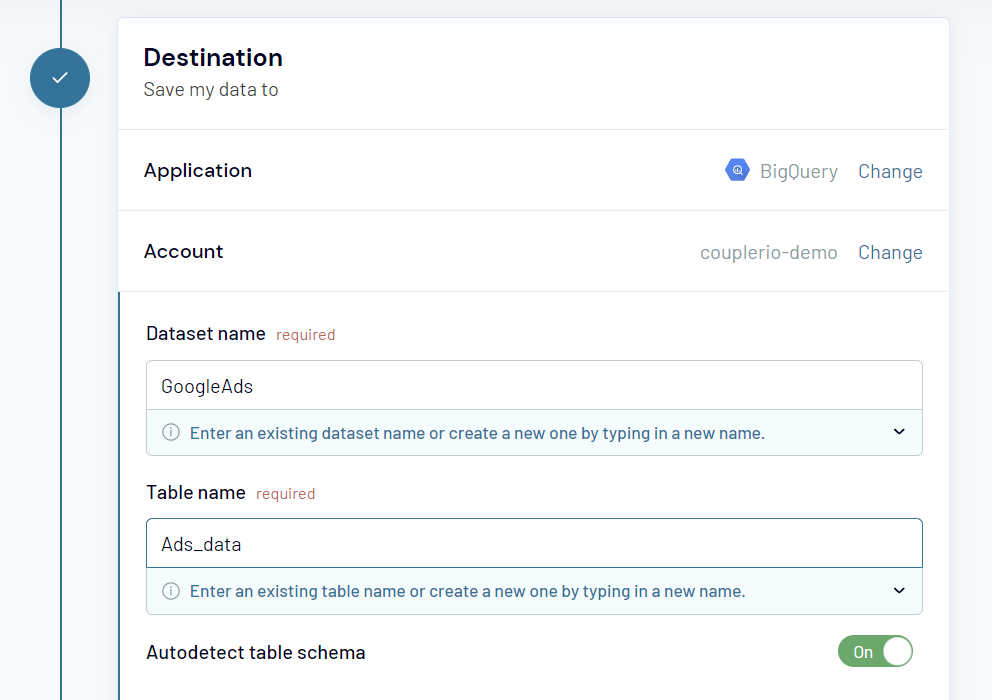
- Then connect your BigQuery account and specify the names of the dataset and table where your Google Ads data will be loaded. You can create a new dataset and a table by typing new names.
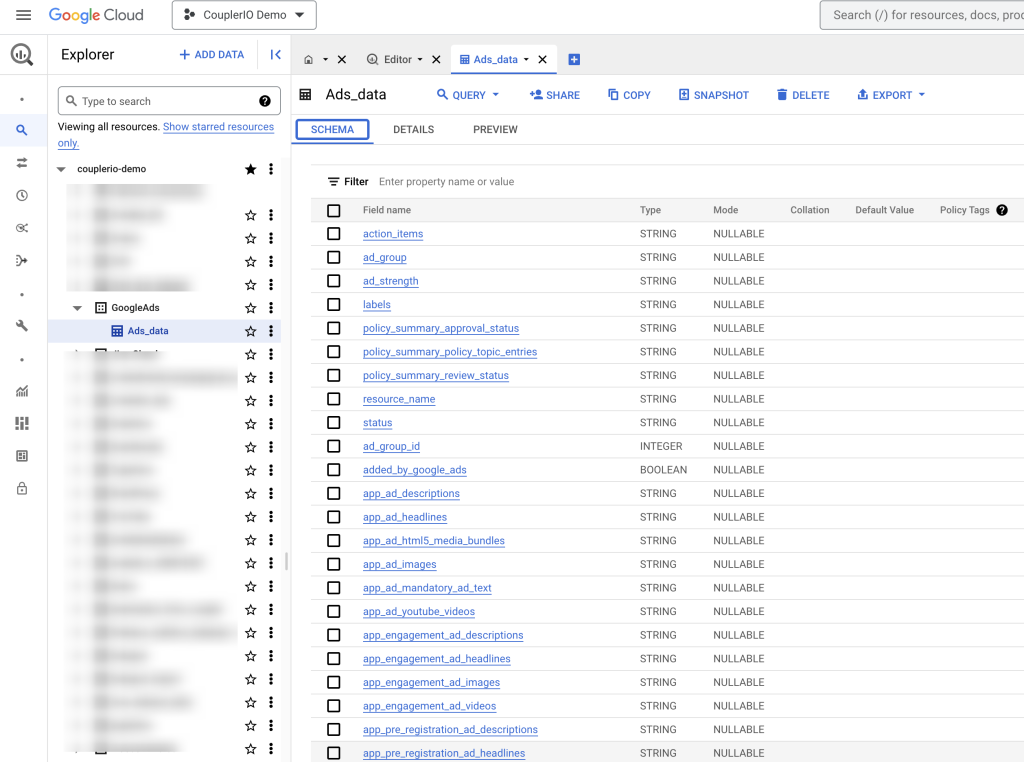
You can run the importer right away or automate data extraction on a schedule with the help of the Automatic data refresh feature. Here is what the extracted data looks like in BigQuery.
You can then transform this data for analysis or reporting. Coupler.io, being an automation and analytics platform, provides a data analytics consulting service to cope with different types of data visualization or more advanced data management tasks.
The choice of a data extraction tool should rest on the type of data that needs to be extracted and its format. Other essential choice factors are usability, cost, support, etc.
You can also consider the accessibility of the tool – whether it’s open-source or commercially available. Open-source tools are typically free, which makes them attractive for projects with limited budgets. Commercial data extractors are robust solutions that can boast increased reliability and actionable features.
What are the benefits of using an extraction tool?
Automating the data extraction workflows can also help to reduce manual effort and free up resources for other tasks. Obviously, when relying on data extraction software, there is a wide range of benefits. We’ve covered most of these:
- Cost efficiency
- Increased efficiency
- Improved data quality
- Enhanced data integration
- Scalability
- Ease of use
What are the common data extraction business challenges and how to overcome them?
Data extraction is a long and intricate process that costs companies lots of time. Despite its importance, it has its specific challenges related to quality, privacy, or volume of data. Let’s check out these and other challenges you may face and the steps to take to overcome these challenges.
Data extraction challenge #1: Quality
Data quality issues can result in incorrect insights and decision-making. Data quality improvement can be achieved by implementing data validation rules, standardizing data formats, and launching data quality monitoring and reporting processes.
Data extraction challenge #2: Integration
Integrating data from multiple sources into a single, unified format requires effort to ensure data consistency and analyzability. Using reliable data integration solutions, such as Coupler.io, can be a lifesaver to automate data integration processes.
Data extraction challenge #3: Privacy
The extracted data must be protected from unauthorized access and it has to comply with relevant privacy regulations. You can achieve this by implementing strict access controls, using encryption for sensitive data, and monitoring compliance with privacy regulations.
Data extraction challenge #4: Volume
With the growth of generated data, data extraction needs will also rise. It becomes critical to ensure that the data extraction process can scale to meet increasing data volumes. Using data warehousings and big data technologies, such as Hadoop and Spark, allowing you to scale your extraction capacity and handle large volumes of data.
FAQ about data extraction
The topic of data extraction in ETL is vast and we could proceed to cover other aspects of this concept. However, we decided to focus on key questions that you may have after reading this article.
What’s the difference between data extraction and data export?
In most cases, extracting and exporting data mean the same job. However, there is a conceptual difference between these terms.
Data extraction forms the process of pulling data from a source without changing or processing it. For example, you can extract columns A to H from a dataset.
Data export means to retrieve data but also implies the data will be processed in some way. For example, you can export data from Trello to Google Sheets, which means that the data format will be altered.
In other words, we can state that data export is a process of extracting data into a format required by the destination.
Can you extract data without further transformation and load?
Data extraction as a standalone process is possible. Whereas transformation and load cannot be carried out if no data has been extracted. Nevertheless, if you extract data without being then transformed or loaded, you should understand that such data will unlikely be fit for analysis. E without TL can work for archival purposes or backup in some cases. For tasks related to analysis, reporting, migration, and more, extraction should be followed by transformation and load steps.
What are the common data extraction methods?
- Web scraping to collect data from websites and publicly available web pages.
- API extraction to pull data from social media apps, cloud services, and other online applications using their REST API.
- Database extraction to set up data collection from a database.
- Screen scraping to capture data from legacy systems that cannot be accessed through an API or database query.
- File extraction to gather data from files, such as spreadsheets, CSV files, or PDFs.
You can encounter other data extraction methods including the hybrid ones that cover getting data from multiple sources of different kinds.
Automated data extraction to streamline your reporting and analytics
Data extraction is a crucial aspect of modern business operations since it provides businesses with the information essential for data-driven decision-making. This allows them to stay competitive and drive their success.
The objective of data extraction is to gain concise and clear insight into very specific aspects of a market, business, or customer (consumer). From a B2B standpoint, this includes:
- Uncovering fresh business opportunities: identify new leads, potential customers, etc.
- Gathering competitor info: unlock valuable insights on competitors’ business strategies.
- Tracking market trends: extract market data, discover trends, and capitalize on them.
- Identifying customer pain points and needs: understand the customer base.
- Monitoring and analyzing customer feedback: improve and address current customers’ needs.
- Automating processes: reduce manual labor by using data extraction tools.
The main data extraction objective is to get the data that is needed for your business be it large or small. To kick things off, let’s name a few benefits: improved data analysis, reporting, automation, marketing data visualization, enhanced customer data, and improved data integration.
Data extraction automation is the perfect ticket for businesses. It saves your resources and paves the way for better data analytics and interpretation, which delivers better insights. Automated data extraction creates a number of unique advantages, in addition to leveling the playing field. Essentially, you get the right level of automation for your data integration and data extraction needs, as you export information with ease and efficiency.
