Data is crucial in today’s business world.
In fact, if you don’t maintain track of the different elements that affect operations on a daily basis, it’s practically impossible to make significant moves and experience progress.
Therefore, it is vital to make sure the data is in a correct and usable format. Data cleansing and data transformation are the techniques that will help you achieve this goal.f
Importance of data cleansing and data transformation
Data can be stored in many sources, and it’s challenging to analyze it in such forms. As a result, data warehouses are used. A data warehouse is a central site where data from many databases is consolidated.
Data warehouses assist in the creation of reports, the analysis of data, data presentation, and making critical business decisions. In other words, they aid the overall business analytical process.
In data warehousing, two strategies are used: data cleansing and data transformation. Data cleansing is the act of removing meaningless data from a data set to enhance consistency. In contrast, data transformation is about transforming data from one structure to another to make it easier to handle.
Data cleansing vs. data transformation with example
Let’s look at a practical example to understand the difference between data cleansing and data transformation.
Let’s say we’re running a bookstore, and we’re making a database of all items in our inventory. While recordkeeping inventory, you accidentally recorded a book twice. This will increase the total inventory and later on result in miscalculation.
You can fix this error by using the remove duplicate method during data cleansing. Now your inventory records are accurate.
Your records are now in a data warehouse. However, your accountant requires a PDF file with the complete inventory list. To meet this demand, you’ll perform data transformation and convert the contents of the database into the desired format.
This merging of different datasets into one destination is a common practice, and tools such as Coupler.io can effectively help.
Coupler.io allows importing data from different applications and into a data warehouse (BigQuery) or a spreadsheet app (Excel, Google Sheets). The available sources include Quickbooks, Pipedrive, Airtable, Hubspot, and others.
Common use cases include data stitching of multiple BigQuery tables or Excel worksheets or importing data from Dropbox to Google Drive or OneDrive. All imports occur automatically and run according to your chosen schedule.
What is data cleansing?
Data cleansing, also referred to as data cleaning, is about discovering and eliminating or correcting corrupt, incomplete, improperly formatted, or replicated data within a dataset.
There are numerous ways for data to be replicated or incorrectly categorized when compiled from different data sources. Faulty data leads to inaccurate calculations and results even when the data seems correct.
Here is a list of standard data cleansing methods:
Remove duplicates
When you collect or scrape data from various sources, there’s a good chance you’ll end up with duplicate items. These duplicates could result from human error, such as an error committed by the individual entering data or when filling out a form.
Duplicates will significantly alter your data and/or cause confusion in your results. They can also make data difficult to interpret when you try to visualize it, so it’s preferable to get rid of them as soon as possible.
Remove any data that isn’t relevant
Any analysis you conduct will be slowed and muddled by irrelevant data. So, before you start cleaning your data, you need to figure out what is significant and what isn’t. You don’t need to enter your client’s email addresses, for example, if you’re studying their age range.
Other data you may want to get rid of because they don’t add value to your data are:
- Personally identifiable (PII) data
- URLs
- HTML tags
- Boilerplate text (such as in emails)
- Tracking codes
- Excessive blank space between text
Standardized capitalization
You must ensure that the text across your data is consistent. If you use a combination of capitalization cases, you can end up with distinct, erroneous categories. This might cause issues if you attempt to translate something before processing, because capitalization can alter the meaning.
Chase, for example, can be a person’s name, whereas a chase or to chase is something altogether different. Generally, it is good practice to use lowercase for your text cleansing when processing.
Fix inaccuracies
It goes without saying that you should thoroughly remove any inaccuracies in your data. For example, typographical errors could cause you to miss essential data insights.
You can prevent some of these problems with a quick spell-check. Misspellings or unnecessary punctuation in data such as email addresses could result in you losing contact with your consumers. It’s also possible that you’ll send unintended emails to people who didn’t sign up for them.
Inconsistent format
Inconsistencies in formatting are another type of error. To maintain a constant standard currency, for example, if you have a column of US dollar figures, you must convert every other currency type into US dollars. This holds true for all other types of measurement units as well.
Clear formatting
If your data is excessively structured, machine learning models will not be able to process it. If you’re gathering information from various sources, you’ll undoubtedly encounter a variety of document formats. This can lead to data that is both confusing and inaccurate.
Any formatting performed on your documents should be removed so that you may start from a consistent data set. This is usually not a complicated process, as both Excel and Google Sheets provide an essential standardization feature.
Handle missing values
You have three possibilities when it comes to incomplete data:
- Remove all observations with missing values.
- Fill in the blanks.
- Leave blanks as-is.
What you do depends on your analytical aims and what you want from the data.
Eliminating missing values entirely may result in the loss of vital information from your data. Besides, there may have been a reason that you wanted to get this information in the first place.
As a result, it might be preferable to fill in the blanks by researching what data may belong in that field. If you can’t figure it out, you may use the word “missing” instead. If the field is numeric, you can put a zero value if that is consistent with your data.
When there are so many errors that there isn’t enough data to use, you should remove the entire section.
What is data transformation?
Data transformation is about converting data from one format to another, usually from a source system’s format to the desired format. Most data integration and management operations, such as data wrangling and data warehousing, need data transformation.
Data transformation methods include:
- Integration.
- Filtering.
- Scrubbing.
- Discretization.
- Duplicate Removal.
- Attribute Construction.
- Normalization.
More on these methods in our data transformation guide.
What is the difference between data cleansing and data transformation?
The process and outcome are different for data cleansing and data transformation.
During data cleansing, first, the dataset is inspected and profiled. Through the inspection, errors are detected. Then the errors are corrected, and the inconsistencies are addressed.
Once the issues are addressed, the dataset is checked again for verification, after which the details of the cleaning process are reported to the management.
Whereas in data transformation, the data is discovered from the source format, and the actual transformation process is planned, also known as data mapping. Afterwards, it is converted into the desired format.
While data cleansing ensures data accuracy, allowing for the analysis and decision-making of only high-quality data, data transformation enables datasets to be converted into different accessible formats.

Explaining the pros and cons of data cleansing
Having clean data will enhance overall productivity and help you make decisions based on the best quality information available.
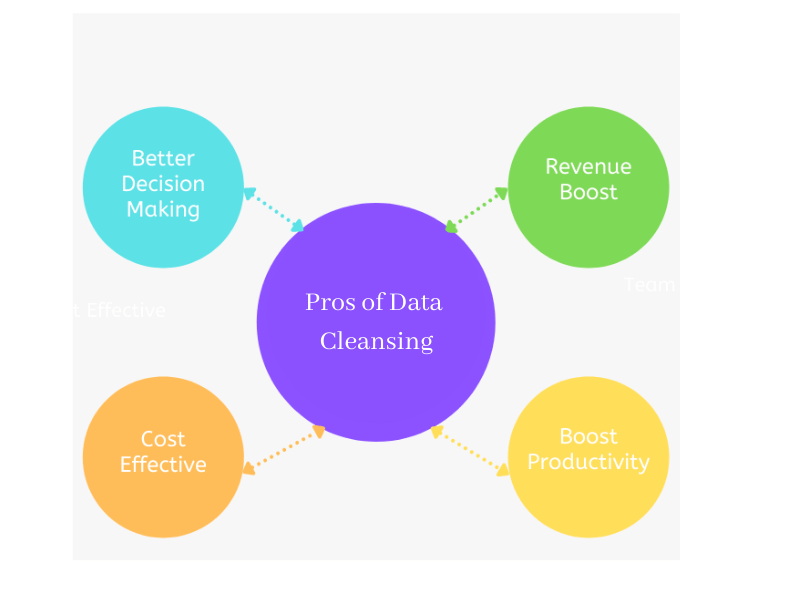
The following are some of the advantages of data cleansing:
- Data cleansing will aid in the removal of erroneous data that could lead to poor decision-making. A business owner, for example, can make an informed decision on whether to sell or buy based on current market knowledge.
- Businesses with accurate demographic information on their target population can use the most effective marketing strategies. More clients, sales, and money revenue will result from this.
- Businesses can be sure of a high engagement rate when they work with the correct marketing database, giving them the optimal value for their money. This will reduce the amount of money spent on unproductive marketing strategies.
- Employees will spend less time contacting expired contacts or clients with outdated information if they have correct and up-to-date information.
Cons of data cleansing:
- Due to inadequate data, analysts may miss out on relevant insights. When missing records and anomalies are discarded, this is fairly common. When this process is automated, it may exacerbate the problem.
- A few automated data cleaning technologies aren’t particularly sophisticated, and they may end up misusing some dataset observations.
- Data cleansing may require a lot of time, especially when working with significant amounts of data.
- The procedure can be costly depending on the size of the data and the degree of corrections required.
Explaining the pros and cons of data transformation
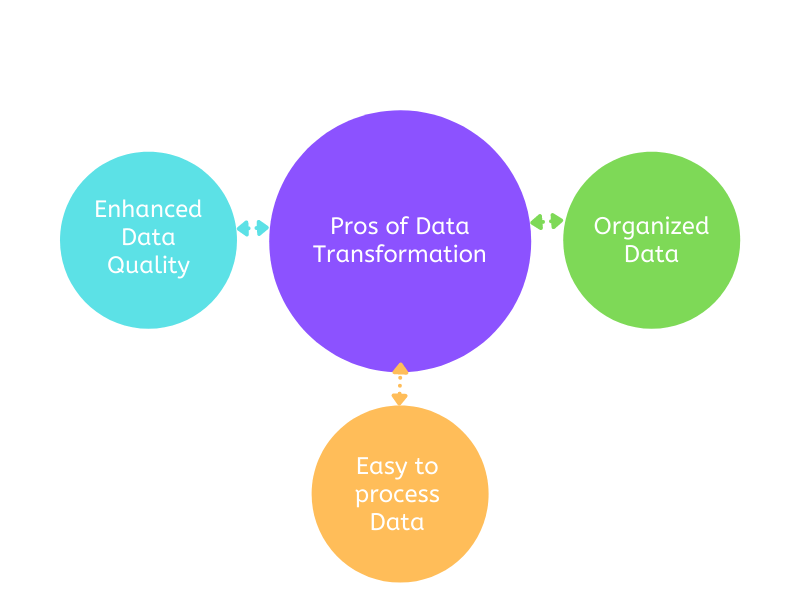
There are several advantages to transforming data:
- It’s easier to work with transformed data both for humans and machines. We transform data to make it more organized.
- Undocumented data can be avoided with adequately structured and verified data; by unintended duplicates, incorrect referencing, and incompatible formats. This will enhance data quality and shield programs from potential hazards.
- Data transformation makes it simpler to integrate applications, systems, and different data types to work collectively. Data that is utilized for several purposes may require different transformations.
Cons of data transformation:
- Data transformation may be expensive. The price is determined by the equipment, software, and tools utilized to process data. Licensing, technology resources, and recruiting appropriate employees are other possible expenses.
- Data transformations can be time-consuming and resource-intensive. Performing transformations after loading data into an on-premises data warehouse or altering it before delivering it into apps might strain other operations. Because the platform can scale up to meet demand, you can conduct the changes after loading if you employ a cloud-based data warehouse.
- During the transition, a lack of competence and negligence might cause issues. Because analysts may be unfamiliar with the scope of valid and allowed data values, data analysts without proper subject matter experience are less likely to detect typos or inaccurate data. For example, someone working with medical data who is inexperienced with relevant medical terminology may misspell illness names, or fail to highlight disease terms that should be mapped to specific values.
- Enterprises can undertake conversions that do not meet their requirements. A company may alter data to a specific format for one application, only to restore the information to its previous format for another purpose.
- As businesses’ decision making and strategic planning become more data-driven, accurate and accessible data is even more of a necessity. Coupler.io can help automate the process of data transformations and increase data efficiency.
Data cleansing vs. data transformation – summary
The significance of these techniques is increasing as companies rely more and more on data to make decisions. Data cleansing and data transformation are two different techniques to utilize data efficiently.
While data cleansing improves the accuracy and consistency of your data, data transformation techniques help you convert it into useful information.
Enhancing data quality by collecting, managing, and transforming data is a critical first step toward making more intelligent business decisions. This vital step will help your company build a strong data culture.
